MAGRPO: Training LLMs That Truly Collaborate with Multi-Agent Reinforcement Learning
Why Independent Fine-Tuning Fails When LLMs Need to Collaborate
Multi-Agent LLM systems are common now: one handles planning, one writes code, one reviews, one summarizes. It sounds like an efficient team, but in practice a problem often appears: temporarily organizing multiple LLMs with prompts does not mean they have truly learned to collaborate.
The MAGRPO interpreted in this Bohrium article—short for Multi-Agent Group Relative Policy Optimization—tries to reframe “how LLMs collaborate” from a prompt-engineering problem into a multi-agent reinforcement learning problem. The core idea is: don’t rely only on prompts to make multiple models “look like they’re cooperating”; instead, during training, use shared rewards so they learn to jointly optimize a team objective. (Bohrium)
1. Why do ordinary multi-agent prompts often fail?
Many multi-agent systems are essentially test-time orchestration: the models don’t change; they just exchange outputs at inference time through debate, discussion, review, sequential pipeline, and so on. The problem is that these Agents were not trained as a team—they are merely prompted to “cooperate” temporarily. The original paper points out that such methods are prone to inefficient communication, unstable role adherence, mutual propagation of incorrect information, and unclear prompt/role design. (ar5iv)
Another approach is to fine-tune each Agent independently—for example, designing separate rewards for a “planner,” “executor,” and “reviewer.” But this introduces two difficulties:
First, reward design is complicated. You must manually decide what reward each role should receive, yet success in collaborative tasks often comes from overall performance, which is hard to decompose into each Agent’s independent contribution.
Second, multi-agent environments are non-stationary. When one Agent’s policy is updated, the “environment” faced by another Agent also changes. This makes each model learn in a constantly changing environment, making convergence harder. The original paper explicitly criticizes such independent-learning methods for lacking reliable guarantees under non-stationary environments. (ar5iv)
So MAGRPO is not trying to solve “how to write better multi-agent prompts,” but rather:
Can we train multiple LLMs around the same team objective during training, and still maintain parallel, efficient, decentralized execution at inference time?
2. MAGRPO’s basic idea: centralized in training, decentralized in execution
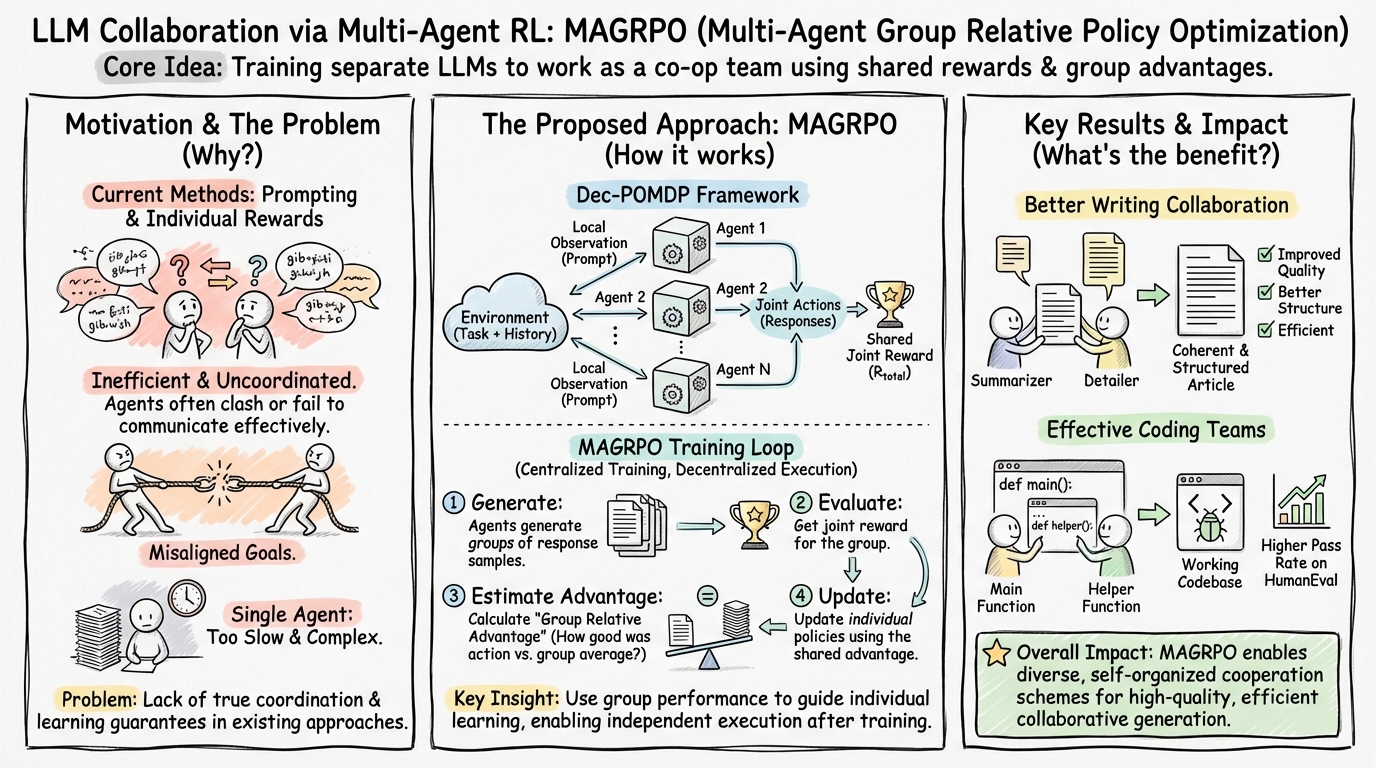
LLM Collaboration via Multi-Agent RL: MAGRPO
MAGRPO models LLM collaboration as a Dec-POMDP, i.e., a Decentralized Partially Observable Markov Decision Process.
It’s a long name, but the intuitive idea isn’t complicated:
Multiple Agents share a final objective, but each Agent can only see its own local input. For example, in collaborative writing, one Agent writes a summary while another fills in details; in collaborative programming, one Agent writes helper functions while another writes the main function. They cannot directly read each other’s internal states; they can only collaborate indirectly via task inputs, historical outputs, or environment feedback. The original paper puts the state, local observations, natural-language responses, shared rewards, and episode limits into the Dec-POMDP framework to describe LLM collaboration tasks. (ar5iv)
MAGRPO adopts a Centralized Training, Decentralized Execution approach:
During training, the system can compute a shared reward from the overall outcome to judge whether the joint outputs of multiple Agents are good.
During execution, each Agent does not need a central controller to guide it step by step; instead, it independently generates based on its local context, and multiple Agents can work in parallel.
This is crucial. Many multi-agent systems are slow because they require round after round of dialogue, waiting on each other, and repeated aggregation. MAGRPO aims for: collaboration learned during training; at inference time, with minimal or even no communication, they can still coordinate naturally.
3. The relationship between MAGRPO and GRPO
MAGRPO is a multi-agent extension of GRPO, i.e., Group Relative Policy Optimization.
A key idea in standard GRPO is: you don’t necessarily need to train an extra value model; instead, you can generate a group of candidate outputs and estimate advantage using relative performance within the group. MAGRPO extends this idea to the joint outputs of multiple Agents.
The training procedure can be roughly understood as:
- Sample a task from the dataset;
- Multiple Agents each generate multiple responses based on their local prompts;
- Combine the outputs of multiple Agents into joint actions;
- The environment or a reward model assigns a shared reward to these joint outputs;
- Use the group average performance as a baseline to compute the relative advantage of each joint output;
- Use that advantage to update each Agent’s policy.
The original paper emphasizes that MAGRPO does not use an explicit value model; instead, it estimates the expected return of the current state via a set of Monte Carlo samples, obtaining a centralized advantage estimate, and then updates each Agent’s policy separately. (ar5iv)
The benefit is: it neither relies on a huge centralized critic like traditional CTDE methods, nor loses team-level feedback like fully independent training. It strikes a compromise between the two with “shared reward + within-group relative advantage.”
4. Experimental results: collaboration isn’t just more rounds of chat—it’s trained
The article and paper mainly present experiments in two directions: collaborative writing and collaborative programming.
4.1 Collaborative writing
The writing experiments include TLDR summarization and arXiv abstract expansion. The system uses two Qwen3-1.7B Agents: one produces a shorter core summary, and the other produces a more detailed summary or expansion. Rewards are composed from metrics such as structure, style consistency, and logical coherence. (ar5iv)
The results are interesting: on the TLDR task, MAGRPO runs at 202.3 tokens/s with a response time of about 2.1 seconds; a single Qwen3-4B model runs at 64.1 tokens/s with a response time of about 6.6 seconds. In other words, two smaller models collaborating in parallel are nearly 3× as fast as one larger model. More importantly, MAGRPO’s normalized return on TLDR reaches 94.5%, significantly higher than one-round discussion at 22.3% and sequential generation at 21.7%. (ar5iv)
This highlights a point: the key to multi-agent systems is not making models “discuss more,” but making them learn stable division of labor during training.
4.2 Collaborative programming
In the programming experiments, the paper has two Qwen2.5-Coder-3B Agents collaboratively generate Python functions: one generates helper functions and the other generates the main function. Their outputs are concatenated into complete code and evaluated by structural completeness, syntactic correctness, unit-test pass rate, and collaboration quality. (ar5iv)
On HumanEval and CoopHumanEval, MAGRPO performs better overall than prompt-based baselines such as naive concatenation, sequential pipeline, and one-round discussion. Especially on CoopHumanEval, which is more suitable for collaborative decomposition, multi-turn MAGRPO achieves a total return of 88.1%, significantly higher than other baselines. (ar5iv)
One detail matters here: many problems in standard HumanEval are not well-suited to being split across two Agents—for example, a short atomic function. The paper therefore constructs CoopHumanEval to give tasks a more collaborative structure. The results show that when the data itself is more amenable to division of labor, MAGRPO training is more stable and yields higher returns. (ar5iv)
This is instructive for engineering: multi-agent setups should not be forced onto every task; they are better for tasks that are naturally modular and have clear feedback signals.
5. What MAGRPO learns is not a fixed pipeline, but collaboration patterns
In collaborative programming, the paper observes that MAGRPO naturally forms several cooperation patterns:
One is fallback. The helper function attempts to implement the core logic, while the main function retains a fallback logic to prevent the whole solution from failing if the helper function is wrong.
One is decorator. The helper function completes the main logic, while the main function handles edge cases, formatting, or extra robustness enhancements.
There are also more proactive patterns, such as the main function acting like a coordinator to decompose the problem, or the helper function acting like a strategy filter to guide the main function in handling specific cases. The paper argues these collaboration patterns emerge naturally under a simple shared reward. (ar5iv)
This is the most noteworthy aspect of MAGRPO: it doesn’t hard-code a workflow; it lets multiple Agents learn task-appropriate collaboration strategies under reward-driven learning.
6. What scenarios is it suitable for?
MAGRPO is best suited for tasks like the following:
Tasks can be decomposed into multiple relatively stable roles, such as summarization/expansion, main function/helper function, frontend/backend, planning/execution.
Tasks have automatically verifiable or semi-automatically verifiable reward signals, such as unit tests, format checks, structural constraints, style consistency, integration test results.
Inference speed matters; you want multiple small models to run in parallel rather than one large model doing everything serially.
Tasks recur frequently, making it worthwhile to “distill” collaboration patterns into model weights through training, rather than coordinating via prompts each time.
The article also notes that MAGRPO may inspire applications such as software development, creative writing, privacy-preserving diagnosis, and multi-role financial analysis. But many of these are long-term visions; real deployment still depends on verifiable rewards, data quality, and safety controls. (Bohrium)
7. Limitations: this is not yet a “general team-training method for Agents”
MAGRPO’s limitations are also clear.
First, current experiments focus mainly on short-horizon tasks, such as summarization, expansion, and function-level code generation. Long-horizon tasks—full software projects, long novels, multi-day research workflows—may still require explicit communication, shared memory, and staged planning. The Bohrium article also notes that current results do not prove this implicit coordination can reliably scale to extremely long-context scenarios. (Bohrium)
Second, reward design has not disappeared; it has merely shifted from “hand-design rewards for each Agent” to “design a shared reward for the joint output.” In coding tasks, unit tests provide natural feedback; but in open-ended product design, complex research, or business decisions, what counts as a good outcome is not always easy to quantify.
Third, MAGRPO’s advantage is strongly tied to data structure. In the paper, CoopHumanEval is more suitable for collaboration than the original HumanEval, so it performs better. This shows that when training multiple Agents, whether the dataset itself has a decomposable structure is crucial. (ar5iv)
Finally, most baselines in the paper are still prompt-based methods rather than other strong fine-tuned multi-agent methods. Thus, MAGRPO demonstrates that “training for collaboration beats temporary prompt collaboration,” but further comparisons against more multi-agent training algorithms are still needed.
8. Implications for Agent engineering
The biggest takeaway MAGRPO brings to Agent system design is: collaboration should not remain only at the prompt-orchestration layer; it should move into the training-objective layer.
Today, many Agent frameworks focus on “building a pipeline”: who speaks first, who speaks next, who reviews, who summarizes. This direction is useful, but it’s more like organizing a meeting of people who have never worked together. MAGRPO’s approach is closer to training a long-term team: each member doesn’t need to hold a meeting at every step, but knows their position, what to output, and how to combine with others’ results to achieve a globally optimal outcome.
For engineering practice, it can be summarized in three sentences:
First, don’t assume “more Agents = stronger.” Without shared objectives and feedback signals, multi-agent systems may just be more expensive, slower, and harder to debug.
Second, prioritize tasks with clear verification signals for multi-agent training, such as code generation, data processing, report generation, and structured writing.
Third, parallel collaboration among small models can be more efficient than serial execution by a single large model—but only if those small models have been trained for collaboration rather than relying solely on prompt-based division of labor.
Conclusion
MAGRPO’s value is not only that it proposes a new algorithm, but that it re-centers the multi-agent LLM problem:
The real difficulty of multi-agent systems is not getting models to talk to each other, but getting them to form stable, generalizable, and parallelizable collaboration strategies around the same objective.
If Agent systems are to move from demos to real production environments, prompt orchestration alone may not be enough. Multi-agent reinforcement learning methods like MAGRPO may become one of the key paths to training “professional AI teams.”
References: the Bohrium interpretation, the arXiv paper “LLM Collaboration With Multi-Agent Reinforcement Learning,” and the authors’ open-sourced CoMLRL framework. CoMLRL provides MARL algorithm implementations for training multiple LLMs to collaborate, and includes environments and benchmarks for writing, coding, Minecraft, and more. (Bohrium)