DDIA 1-4 存储与检索
OLTP
在 OLTP(事务型处理) 系统中,存储引擎通常分为两种主要的架构:
- 日志结构方法:这种方法只允许追加写入数据,旧数据会被删除,但不会修改已写入的文件。常见的存储引擎如 SSTable、LSM 树、RocksDB、Cassandra、HBase、Scylla 和 Lucene 都采用这种架构。日志结构存储引擎在写入吞吐量上表现非常高效。
就地更新方法:这种方法将磁盘视为一个可以更新的存储区域,通常以固定大小的页为单位进行数据存储更新。B 树 是这一方法的代表,它被广泛用于关系型 OLTP 数据库,也用于一些非关系型数据库。B 树通常在读取性能上表现更好,响应时间短且读取吞吐量高。
OLAP
列式存储
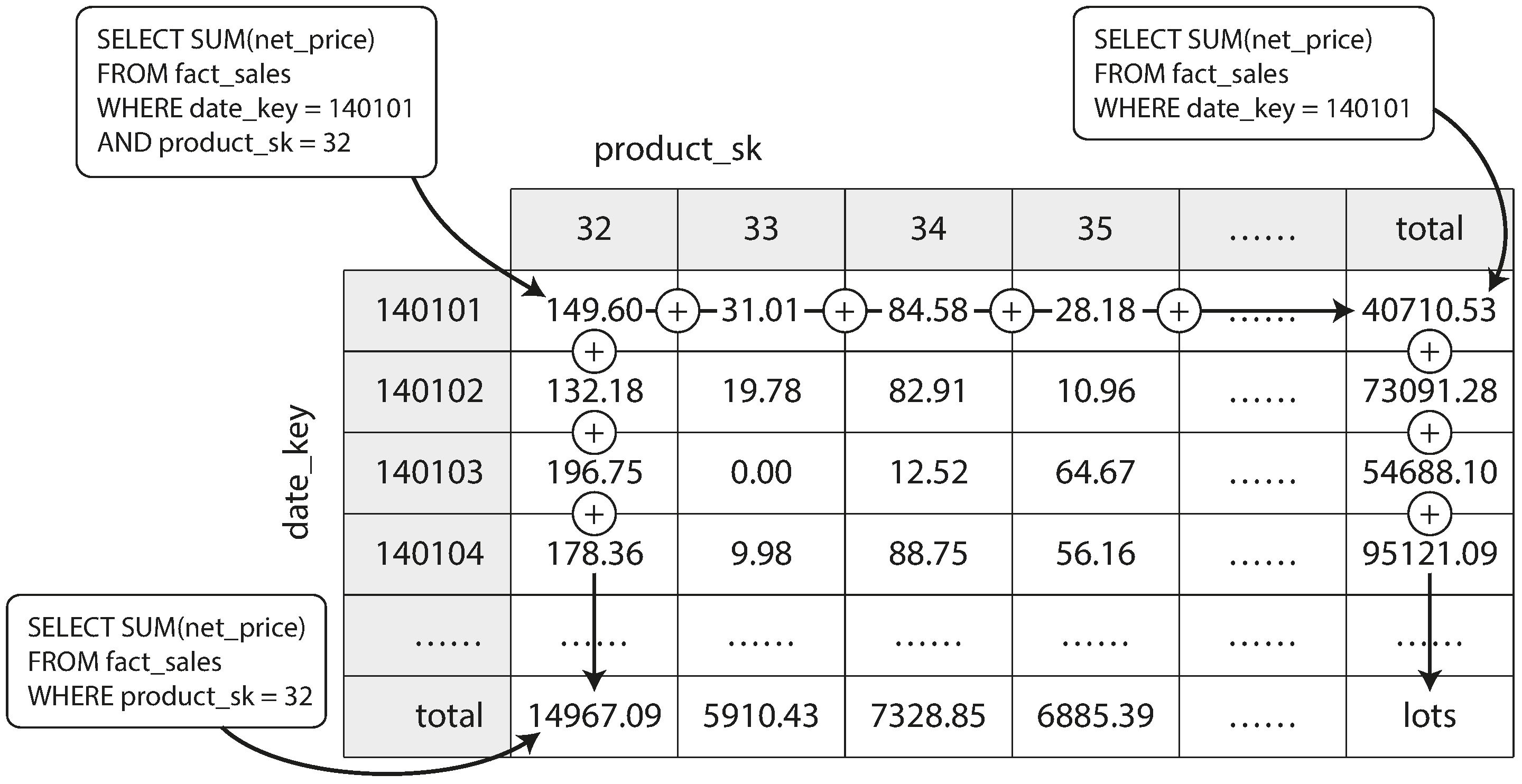
对于 OLAP(分析型处理) 系统来说,最重要的概念之一是 列式存储。在像 星型 或 雪花型 数据模型中,真实表的数据量可能非常庞大(上万亿行数据,数千列),每次分析查询不会涉及到所有列数据,因此列式存储的效率就显得尤为重要。列式存储不仅能提高查询效率,还能节省存储成本。通过列压缩技术(如 位图编码),存储空间得以进一步节省,查询速度也随之提升。
- 位图压缩:采用 RLE(游程编码) 或 咆哮位图(Roaring Bitmaps) 等技术,将重复的数据进行高效压缩,进一步节省空间并提升查询速度。 列式存储的一个优势是,行存储顺序并不重要,例如按日期排序可能会有意义,因为这样可以将同一天的相关数据集中在同一个存储块中。这不仅提升了查询效率,也有助于提高压缩效率,因为相同的值会在数据中连续出现,便于压缩。
列式存储写入
写入列式存储 更适合与 对象存储 配合使用。因为列式存储的数据通常是一次性写入的,且不需要修改。对象存储的分布式特性使得大批量数据写入变得更加高效,而查询时也不需要担心数据存储块是否紧密相邻。
查询优化
查询编译 & 向量化处理
此外,查询优化可以通过 查询编译 和 向量化处理 来加速:
- 顺序内存访问 优于随机访问,减少缓存未命中。
- 在 紧凑的内部循环 中完成大部分计算,避免函数调用的开销。
- 利用 并行处理 和 SIMD(单指令多数据) 指令加速处理。
直接对 压缩数据 进行操作,避免解码,从而节省内存和提高效率。

物化视图 & 多维数据集
另外,物化视图 和 多维数据集 是两种常见的查询优化方式:
- 物化视图:通过将查询结果持久化存储(例如存储在磁盘上)来提升查询性能,但更新不及时是其缺点。
- 多维数据集:通过对聚合函数进行预计算来加速查询。例如,通过计算某一天、某个门店的销售额等聚合信息。
全文检索
倒排索引
对于 全文检索,常用的索引技术是 倒排索引。传统的查询方法是通过 ID 来关联数据行,而倒排索引则是通过 词项(例如文本中的某个词)来关联 文档 ID。倒排索引也可以通过 稀疏位图 进行存储,并通过 按位 AND 或 OR 等运算提高查询速度。
- 倒排索引:它是一个结构,词项是键,文档 ID 的列表是值,允许快速查找包含特定词项的所有文档。假如某个词项出现在多个文档中,我们可以通过位图来表示哪些文档包含该词项,之后通过按位运算快速找到符合条件的文档。
- 三元语法(N-Grams):对于查询中包含特定字符子串的文本,三元语法技术可以将字符串切割为多个子串(例如 "hello" 可以被分为 "hel"、"ell" 和 "llo")。为这些子串构建倒排索引,可以加速对至少三个字符长的任意子串的搜索。
在处理拼写错误时,Lucene 能够在一定的编辑距离内(如增加、删除或替换一个字母)找到相似单词。Lucene 通过 有限状态自动机 和 莱文斯坦自动机 来高效处理这种模糊匹配。
向量化搜索
此外,向量搜索 是现代语义搜索中的关键技术,尤其在 RAG(检索增强生成) 中得到广泛应用。通过 向量嵌入 技术,文档被转换为多维空间中的点,查询时通过比较向量之间的相似度来找到相似的文档。
几种常见的向量索引方法包括:
- 平面索引(Flat Indexes):向量按原样存储,查询时需要逐一计算与查询向量的距离,虽然准确但速度较慢。
- 倒排文件(IVF)索引:将向量空间分为多个簇(质心),减少需要比较的向量数量,查询更快,但结果是近似的。
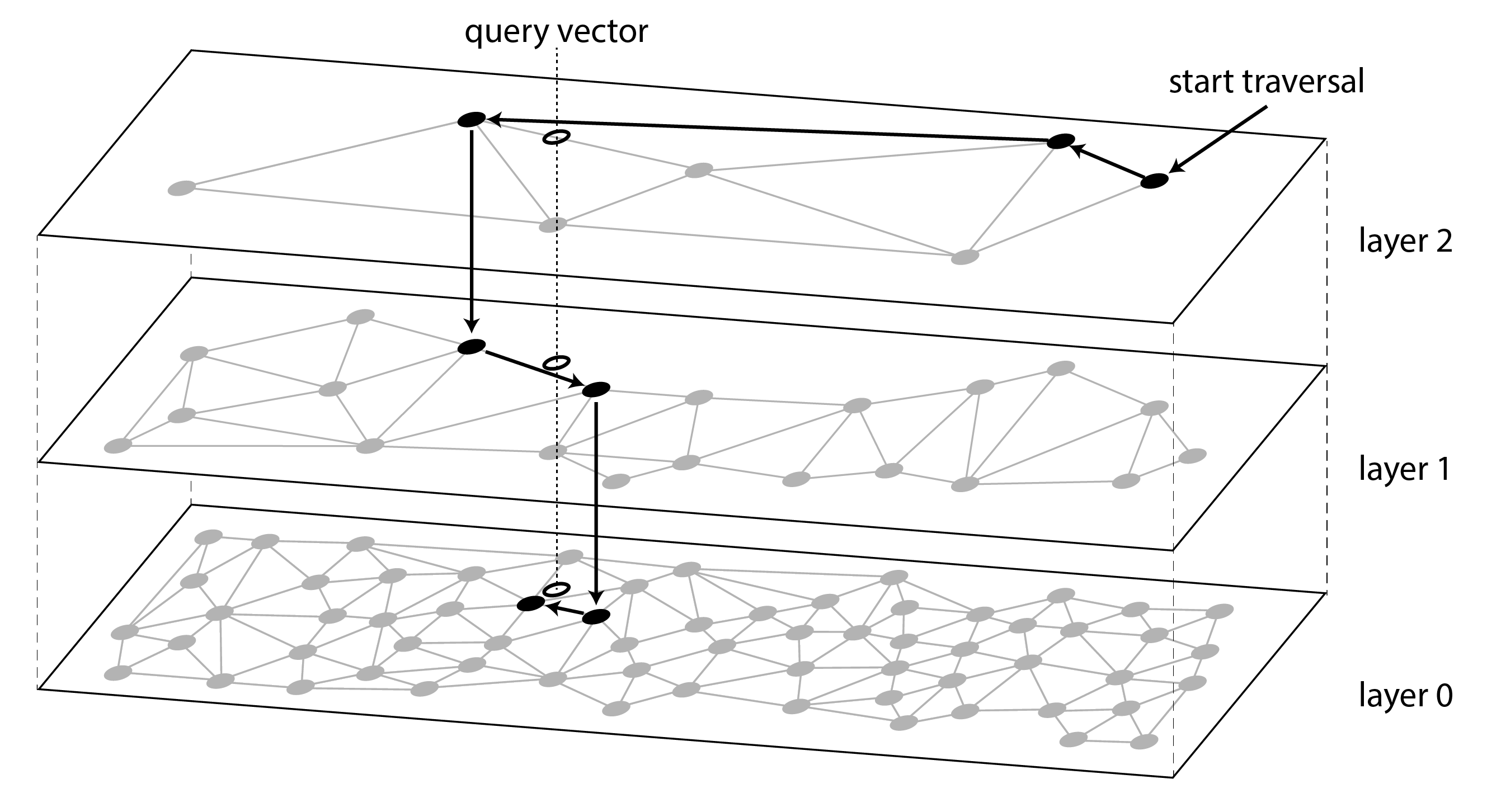
- 分层可导航小世界(HNSW):通过多层图结构维护向量空间,查询时先定位到大致范围,再逐层精细定位,从而找到最接近的向量。
多维索引
- 多维索引:允许同时查询多个列,特别适用于像地理空间数据这种需要同时按多个维度进行筛选的查询。例如,查询餐厅时,可能需要同时按 纬度 和 经度 进行筛选。使用 联合索引 无法高效完成这种查询,但 多维索引 可以一次性处理多个维度。
- 空间填充曲线:一种将二维空间(如经纬度)转换为一维数字的方式,可以将转换后的数字索引到常规的 B 树 上。
- R 树 和 Bkd 树:是专门为多维空间数据(如地理空间)设计的索引结构,通过将空间分割成不同区域,确保相邻的点被分配到相同的子树中,从而提高查询效率。常用于地理空间数据,比如 PostGIS 使用 R 树索引来处理空间数据。
- 网格划分:还可以使用规则间隔的 三角形、正方形或六边形网格 来进行空间分割,有助于优化多维数据查询。
- 应用实例:
- 地理位置查询:餐厅查询系统通过多维索引能高效查找给定范围内的餐厅,避免了使用联合索引时可能出现的效率问题。
- 电子商务网站:可在产品的 颜色(红、绿、蓝) 上使用三维索引,快速查询某个颜色范围的产品。
- 天气观测数据:通过二维索引,可以在日期和温度维度上进行高效查询,避免逐行扫描所有记录。