Reinforcement Learning(RL) & Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning 强化学习

202502101753478
一旦模型在互联网上的数据上经过训练,它仍然不知道如何有效地运用其知识。
监督微调 教会模型模仿人类的回应。
强化学习 (RL) 通过试错帮助模型改进。
强化学习的工作原理

rl-1
强化学习并不依赖于人类创建的数据集,而是让模型尝试不同的解决方案,以找出最有效的方法。
示例过程:
我们生成了15个解决方案。
其中只有4个得到了正确答案。
选择最优方案(既正确又简洁)。
以此进行训练。
重复许多次。
这个过程中没有任何人类参与。模型会针对同一个问题生成不同的解决方案,有时数量甚至达到数百万。然后,它会比较这些方案,挑选出那些得出正确答案的方案,再以这些获胜的方案进行训练。
预训练和后训练过程都已被非常明确地定义,但强化学习过程仍处于大量活跃研究中。Andrej也在这里谈到了这一点。像 OpenAI 这样的公司对此进行了大量研究,但并未公开。这也是 DeepSeek 发布成为大事件的原因。他们的论文详细讨论了这一点,公开阐述了大规模语言模型的强化学习和微调,以及这如何激发出它们的诸多推理能力。
DeepSeek 论文中的一个例子向我们展示,随着时间的推移,模型能够使用更多的 token 来提升其推理能力。

rl-2
你可以看到,模型在这里出现了那种“啊哈”时刻——这不是你能仅通过在数据集上训练就能明确教会它的东西,而是模型必须通过强化学习自行发现的。该技术的优点在于模型的推理能力不断提高,但缺点是它会消耗越来越多的 token。
我们可以从关于围棋大师的研究论文中学到一件事:强化学习实际上帮助模型在推理方面超越了人类同行。模型不仅仅试图模仿人类,而是通过不断试错提出自己的策略以赢得比赛。
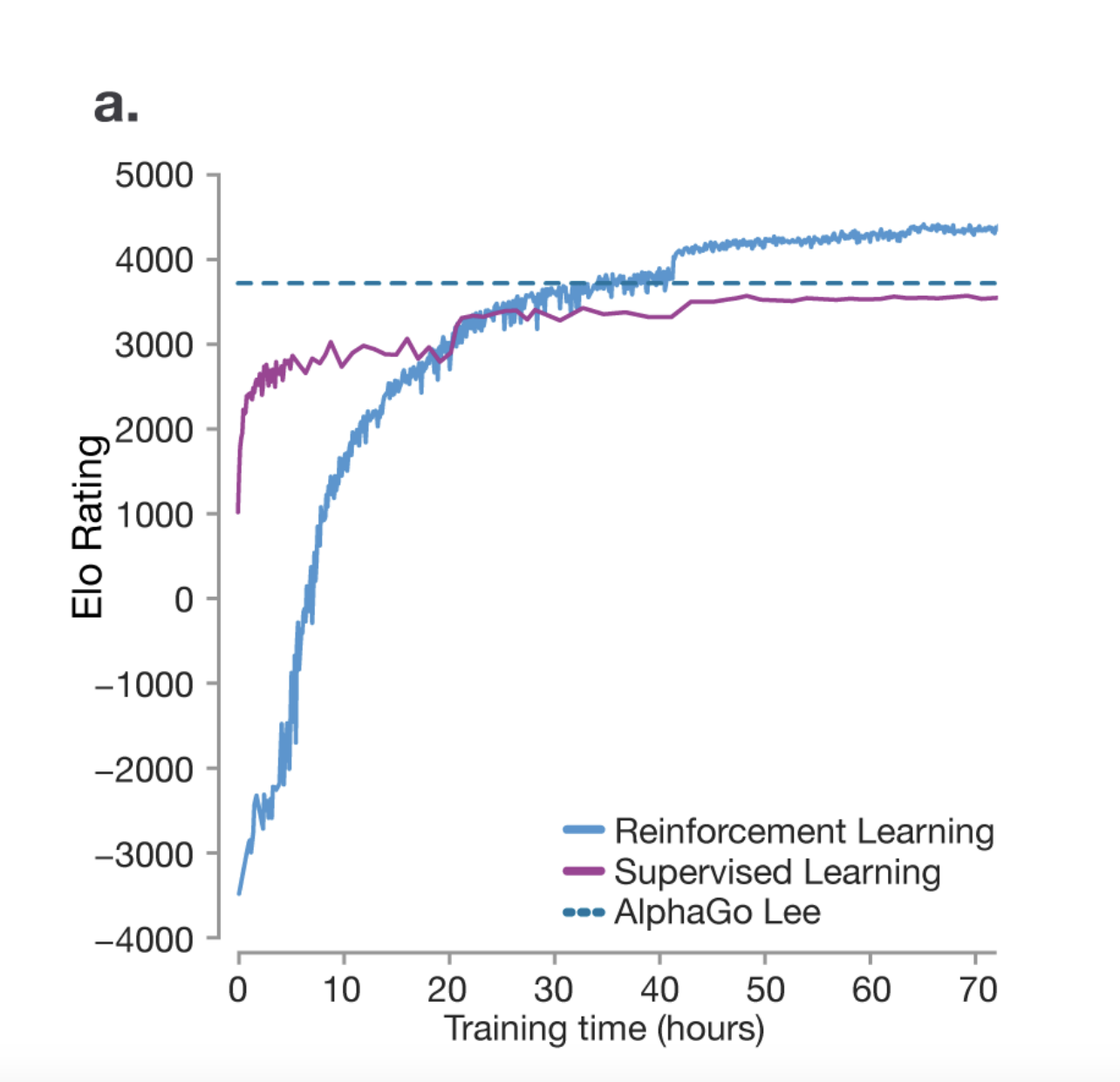
rl-3
AlphaGo 比赛中观察到的一个非常独特的现象是一个被称为第37手的招法。这一招并不在训练数据中,但模型却凭借自己的策略获胜。研究人员预测,人类下出这一招的几率大约为 1/10000。所以,你可以看到模型有能力提出自己的策略。
强化学习仍有许多未被探索的领域,并且在这一方向上有大量研究正在进行。完全有可能的是,如果有机会,大型语言模型可能会创造出一种属于自己的语言来表达其思想和观点,因为它发现这是表达自己想法的最佳方式。
在不可验证领域中的学习,即通过人类反馈的强化学习 (RLHF)
在可验证的领域中,很容易将人类排除在强化学习过程之外,因为大型语言模型可以作为自己表现的评判者。
然而,在不可验证的领域中,我们需要将人类纳入其中。
例如,对于提示 写一个关于鹈鹕的笑话 来说,很难找到一种自动判断笑话质量的方法。大型语言模型可以轻松生成笑话,但无法大规模评判它们的质量。
此外,在大规模过程中包含人类是不现实的。这时就需要 RLHF。你可以在这篇论文中了解更多相关内容。

rlhf-1
为了实现大规模的 RLHF,你基本上需要训练一个独立的奖励模型,这个模型可以是一个不包含额外层的 Transformer。你让人类来评判它对回答的排序,然后利用这些评判结果来训练奖励模型,直到你对结果满意。一旦完成,你就可以利用该奖励模型来大规模评判大型语言模型生成回答的质量。

rlhf-2
RLHF 优点
使得在诸如写笑话或摘要等不可验证领域中能够进行强化学习。
通常通过减少幻觉现象并使回答更具人性化,从而改善模型表现。
利用了“判别器-生成器差距” —— 人类评估答案比生成答案要容易。
例如:“写一首诗” vs. “这五首诗中哪一首最好?”
RLHF 缺点
奖励模型仅是人类偏好的模拟,并非真正的人类,这可能会产生误导。
强化学习可能会利用系统漏洞,产生利用奖励模型弱点的对抗性示例。
例如:经过 1000 次更新后,模型生成的“关于鹈鹕的最佳笑话”可能完全变成胡言乱语(例如,“the the the the the the the the”)。
这种现象被称为对抗性机器学习。由于利用系统漏洞的方法无穷无尽,过滤出不良回答并不容易。
为防止这种情况,奖励模型的训练通常限制在几百次迭代内——超过这个次数,模型便会过度优化,导致性能下降。