BPE(byte-pair-encoding)
解决的问题
BPE(Byte Pair Encoding)是一种用于文本数据处理的子词分词算法,它在自然语言处理中非常常见。BPE的核心目标是解决词汇量过大和稀有词汇处理的问题。
核心就是解决用少量的字符编码表来应对多种未知的词汇变形和组合.
如果穷举这个世界上的所有语言和词汇的话我们就需要一个巨大的映射表. BPE可以解决这种问题, 还可以减少内存占用, 提高模型的效率
BPE的原理
BPE通过逐步合并出现频率较高的字符或子词对,来构建更紧凑的词汇表。在初始阶段,BPE将文本中的每个字符视为一个独立的符号。然后,通过以下步骤来生成更高层级的子词单元:
- 统计频率:统计当前文本中所有字符对的出现频率(即连续的两个字符)。
- 合并最高频的字符对:找到出现次数最多的字符对,然后将其合并为一个新的子词。
- 更新文本:在文本中用新的子词替换原来的字符对。
- 重复上述过程:反复执行上述步骤,直到生成了预定数量的子词或达到预定的词汇表大小。
通过这样的方式,BPE可以逐渐从字符级别构建到子词、词汇级别。由于BPE是基于统计数据的,因此高频词会更容易合并,而低频词则会以子词形式保留。
BPE使用的例子
# pip install tiktoken
from importlib.metadata import version
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
# [15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250,
# 8812, 2114, 286, 617, 34680, 27271, 13]
strings = tokenizer.decode(integers)
print(strings)
# Hello, do you like tea? <|endoftext|> In the sunlit terraces of
# someunknownPlace.
从上述例子中可以看出 <|endoftext|> 被编码为50256, gpt2的tokenizer最大编码表为50257.
而且 someunknownPlace 这个词语可以被正确的编码
BPE背后的算法将不在其预定义词汇表中的单词拆分成更小的子词单元或甚至单个字符,从而使其能够处理词汇表外的单词。
以下是BPE理解Akwirw ier的例子
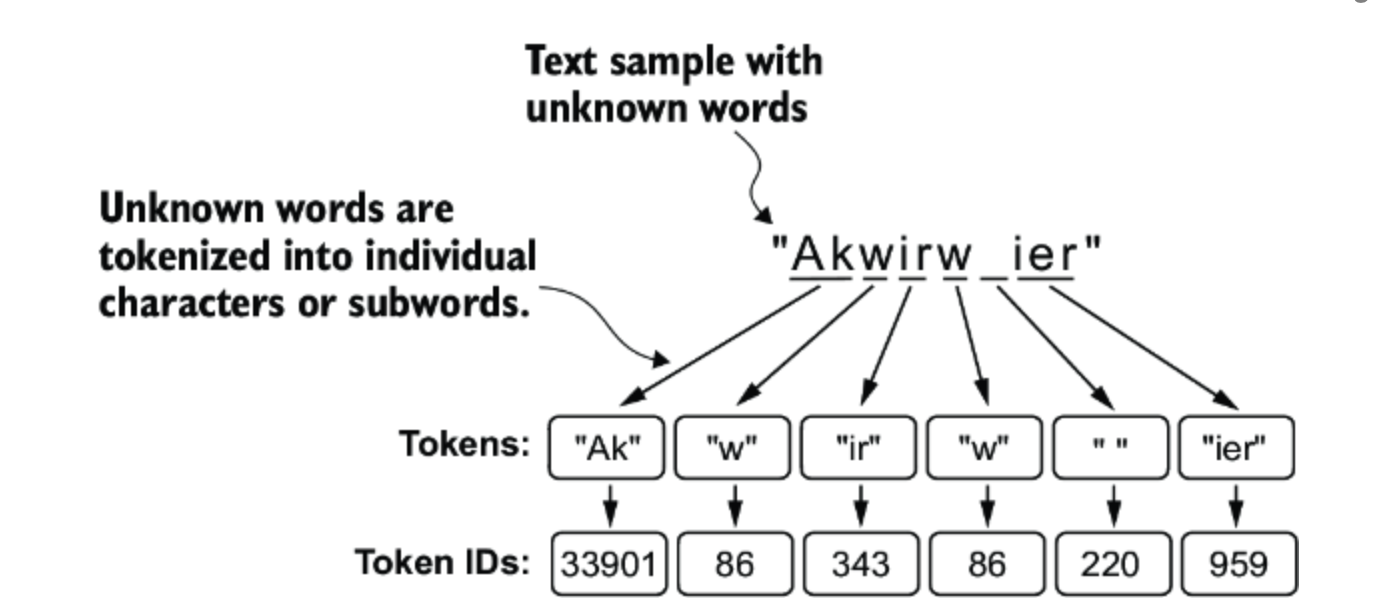
CleanShot 2024-10-08 at 5 .03.54@2x.png
简单总结
但简单来说,它通过反复将频繁出现的字符合并成子词,再将频繁的子词合并成词来构建词汇。例如,BPE首先将所有单个字符(如“a”、“b”等)添加到词汇中。在下一阶段,它将经常一起出现的字符组合合并成子词。例如,“d”和“e”可以合并成子词“de”,这个组合在许多英语单词中很常见,如“define”、“depend”、“made”和“hidden”。合并的依据是频率阈值。