构建AGI产品的Patterns
生成式 AI 产品从概念验证到生产的过渡已被证明是全球软件工程师面临的一个重大挑战。我们认为,许多这些困难源于人们认为这些产品仅仅是传统交易或分析系统的扩展。在与这项技术的接触中,我们发现它们引入了一系列全新的问题,包括幻觉、无界数据访问和非确定性。
有一些常规的 Patterns 可以帮助我们来规避这些问题,以下是对这些 Pattern 的经验一些阐述
- Direct Prompting
- Embeddings
- Evals
- Hybird Retriever
- Query Rewriting
- Reranker
- Retrieval Augmented Generation (RAG)
直接提示 Direct Prompting
CleanShot 2025-02-14 at 09.34.05@2x.png
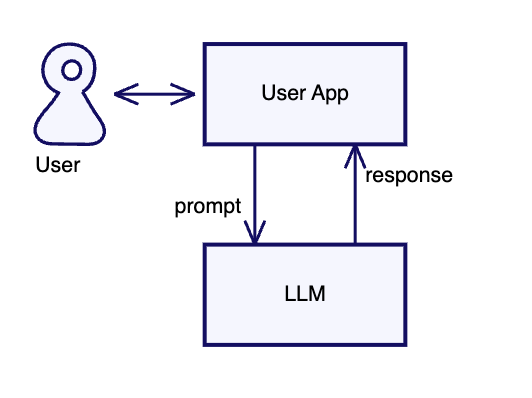
使用 LLM 的最基本方法是直接将现成的 LLM 连接到用户,使用户能够向 LLM 输入提示并直接接收响应,无需任何中间步骤。这就是 LLM 供应商可能直接提供的那种体验。
使用场景 When to use
虽然在很多情况下都很适用,但是仍然有一些显著的缺点。
第一个问题就是 LLM 受限于训练数据,不知道训练以来发生的事情。这也意味着 LLM 不知道训练集之外的具体信息。事实上即使在他的训练集之中,他也仍然不了解正在运作的上下文,应该考虑使用知识库与这部分上下文相关的部分。
除了知识库的限制外,还有关于 LLM 将如何表现的关注,尤其是在面对恶意提示时。它能否被欺骗以泄露机密信息,或者能够给出错误的回答?
LMs 有在知识薄弱时表现出自信的习惯,并随意编造看似合理但实则无意义的答案。虽然这可能会很有趣,但如果 LLM 作为 spoke-bot(发言机器人)在行动,这就会变成一个严重的缺陷。
总结 Summary
直接提示是一个强大的工具,但通常不能单独使用。我们发现,为了我们的用户在实际中应用 LLMs,需要采取额外措施来处理直接提示本身带来的局限性和问题。
我们需要采取的第一步是弄清楚 LLM 的结果究竟有多好。在我们常规的软件开发工作中,我们已经学会了重视测试的价值,确保我们的系统可靠地按照我们的意图运行。
当我们将实践扩展到与 Gen AI 合作时,我们发现建立一套评估模型响应有效性的系统方法至关重要。
评估 Evals
定义 Definition
Evaluate the responses of an LLM in the context of a specific task (评估特定任务中 LLM 的响应)
在传统系统中,我们主要通过测试来实现这一点。我们提供了精心挑选的输入样本,并验证了系统以我们期望的方式响应。
基于 LLM 的系统,我们遇到了一个不再表现出确定性行为的系统。这样的系统会在重复请求时对相同的输入提供不同的输出。这并不意味着我们不能检查其行为以确保它符合我们的意图,但这确实意味着我们必须以不同的方式思考。
Gen-AI 通过“评估”来检查行为,通常简称为“evals”。虽然可以在单个输出上评估模型,但更常见的是评估其在各种场景下的行为。这种方法确保所有预期的情况都得到处理,并且模型输出符合预期标准。
评估 Scoring and Judging
Scorer 评分器是一个组件或函数,它为生成的输出分配数值分数,反映了评估指标,如模型输出与预期答案之间的相关性、连贯性、事实性或语义相似性。

CleanShot 2025-02-14 at 09.54.25@2x.png
不同的评估技术基于谁计算分数而存在,这引发了一个问题:最终将由谁来充当评判者?
- Self evaluation 自我评估: 自我评估允许 LLMs 自我评估并提升他们的回答。尽管有些人 LLMs 在这方面做得比其他人更好,但这种方法存在一个关键风险。如果模型的内部自我评估过程有缺陷,它可能会产生看起来比实际上更自信或更精致的输出,从而导致后续评估中错误或偏差的强化。虽然自我评估是一种技术,但我们强烈建议探索其他策略。
- LLM as a judge LLM 评估: LLM 的输出通过另一个模型进行评分,这个模型可以是更强大的 LLM 或专门的 Small Language Model (SLM)。虽然这种方法涉及使用 LLM 进行评估,但使用不同的 LLM 有助于解决自我评估的一些问题。由于两个模型犯相同错误或存在相同偏差的可能性很低,这种技术已成为自动化评估过程的流行选择
- Human evaluation 人类评估: Vibe checking 是一种评估 LLM 回复是否与期望的语气、风格和意图相符的技术。它是一种非正式的方法来评估模型“是否理解”并以适合情况的方式回应。在这种技术中,人类手动编写提示并评估回复。虽然难以扩展,但这是检查自动化方法通常遗漏的元素的最有效方法。
根据经验,将 LLM 评估与人工评估相结合,对于了解 LLM 在通用人工智能产品关键方面的表现更为有效。这种组合通过利用自动化判断和人类洞察力,增强了评估过程,确保对 LLM 性能有更全面的了解。
运行评估 Running the Evals
与测试一样,我们在构建流程中运行评估作为 Gen-AI 系统的部分。与测试不同,它们不是简单的通过/失败结果,相反,我们必须设置阈值,并附带检查以确保性能不会下降。在许多方面,我们将评估视为与性能测试类似的方式处理。
一个实时生成式 AI 系统在生产过程中可能会改变其性能。因此,我们需要对部署的生产系统进行定期评估,再次寻找我们分数的任何下降。
评估可以针对整个系统,以及任何具有 LLM 的组件。Guardrails 和 Query Rewriting 包含逻辑上不同的 LLMs,可以单独评估,也可以作为整个请求流程的一部分。
评估和基准测试 Evals and Benchmarking
基准测试是建立一组明确定义的任务的基线,以比较 LLMs 的输出。在基准测试中,目标是尽可能减少变异性。这通过使用标准化数据集、明确定义的任务和已建立的指标来持续跟踪模型性能随时间的变化来实现。
因此,当发布模型的新版本时,您可以比较不同的指标,并做出明智的决定是升级还是保持当前版本。
与通用基准测试不同,评估用于衡量我们特定任务中 LLM 的输出。没有行业公认的评估数据集,我们必须创建一个最适合我们用例的数据集。
使用评估的难点在于,我们对哪些机制最适合评分和判断的理解仍处于早期阶段。尽管如此,我们认为评估对于在我们可以放心用户对 LLM-系统持健康怀疑态度的情况下使用基于 LLM-的系统至关重要。
嵌入 Embedding
定义 Definition
Transform large data blocks into numeric vectors so that embeddings near each other represent related concepts (将大数据块转换为数值向量,以便彼此靠近的嵌入表示相关概念)
LLM 中的 Embeddings
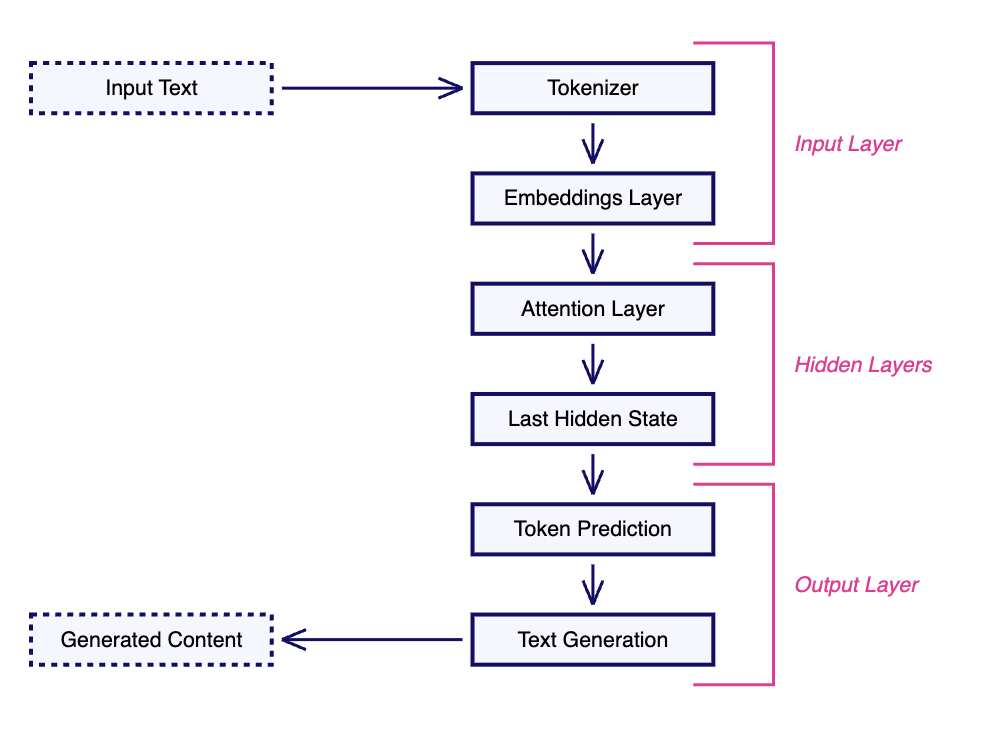
LLM 是一种称为 Transformer 的专用神经网络。虽然它们的内部结构复杂,但可以从概念上分为输入层、多个隐藏层和输出层。
CleanShot 2025-02-14 at 10.02.59@2x.png
输入层的一个重要部分是 LLM 词汇的嵌入。这些被称为 LLM 的内部、参数化或静态嵌入。
LLM 执行以下逻辑步骤以生成响应。
- 在输入层,分词器将输入提示文本和图像转换为嵌入。
- 然后,这些嵌入被传递到 LLM 的内部隐藏层,也称为注意力层,从中提取输入中存在的相关特征。假设我们的模型是在营养数据上训练的,不同的注意力层从健康和营养的角度分析输入
- 最后,使用最后一个隐藏状态(即最后一个注意力层)的输出进行预测。
使用场景 When to use it
嵌入捕捉数据的意义,以实现项目之间的语义相似性比较,例如文本或图像。与关键词或模式的表面匹配不同,嵌入编码了更深层次的关系和上下文意义。
因此,生成嵌入涉及运行专门的 AI 模型,这些模型通常比大型语言模型更小、更高效。一旦创建,嵌入可以用于高效地进行相似度比较,通常依赖于简单的向量运算,如余弦相似度
然而,嵌入并不适合结构化或关系型数据,在这些情况下,精确匹配或传统的数据库查询更为合适。如查找精确匹配、执行数值比较或查询关系等任务,比嵌入和向量存储更适合使用 SQL 和传统数据库。
评估为我们提供了一种评估系统整体能力的方法,而嵌入提供了索引大量非结构化数据的方法。LLMs 是在这些数据的语料库上训练的,或者如社区所说“预训练”。对于一般情况,这很好,但如果我们想让模型利用更具体或更新的信息,我们需要 LLM 了解预训练集之外的数据。
一种将模型适应特定任务或领域的方法是进行额外训练,这被称为微调。问题是这样做非常昂贵,因此通常不是最佳方法。对于大多数情况,我们发现最佳路径是采用 RAG。
检索增强生成 (RAG) Retrieval Augmented Generation
定义 Definition
Retrieve relevant document fragments and include these when prompting the LLM
(检索相关文档片段,并在提示 LLM 时包含这些内容)
一个常见的比喻是,LLM 是一个初级研究员。这样的人能言善辩,一般知识渊博,但对主题的细节了解不足——并且过于自信,宁愿编造一个合理的答案,也不愿承认无知。在 RAG 中,我们向这位研究员提出一个问题,并给他们提供一份包含最相关文件的档案,告诉他们在给出答案之前阅读这些文件。
我们发现 RAGs 是一种使用具有专门知识 LLM 的有效方法。但它们会导致经典的信息检索(IR)问题——我们如何找到合适的文档提供给我们的热情研究员?
常见的做法是使用嵌入构建文档索引,然后使用此索引搜索文档。
这一部分是构建索引。我们通过将文档分成块,为这些块创建嵌入,并将块及其嵌入保存到向量数据库中来实现。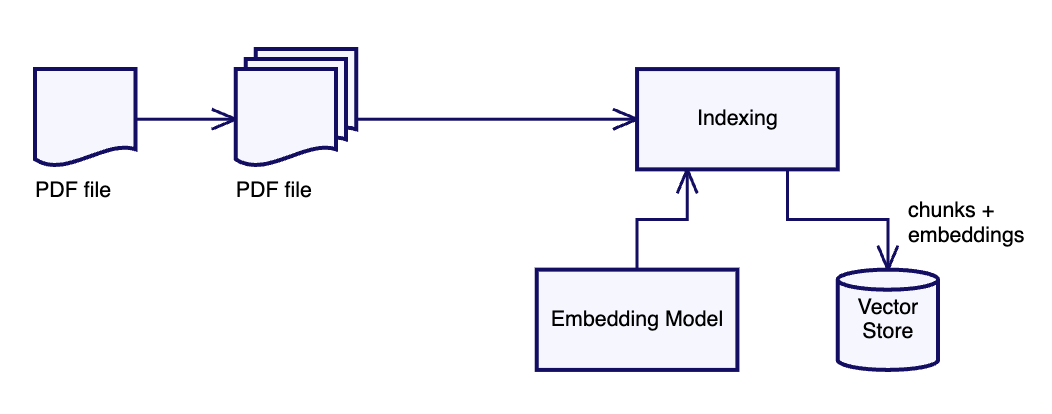
CleanShot 2025-02-14 at 10.13.36@2x.png
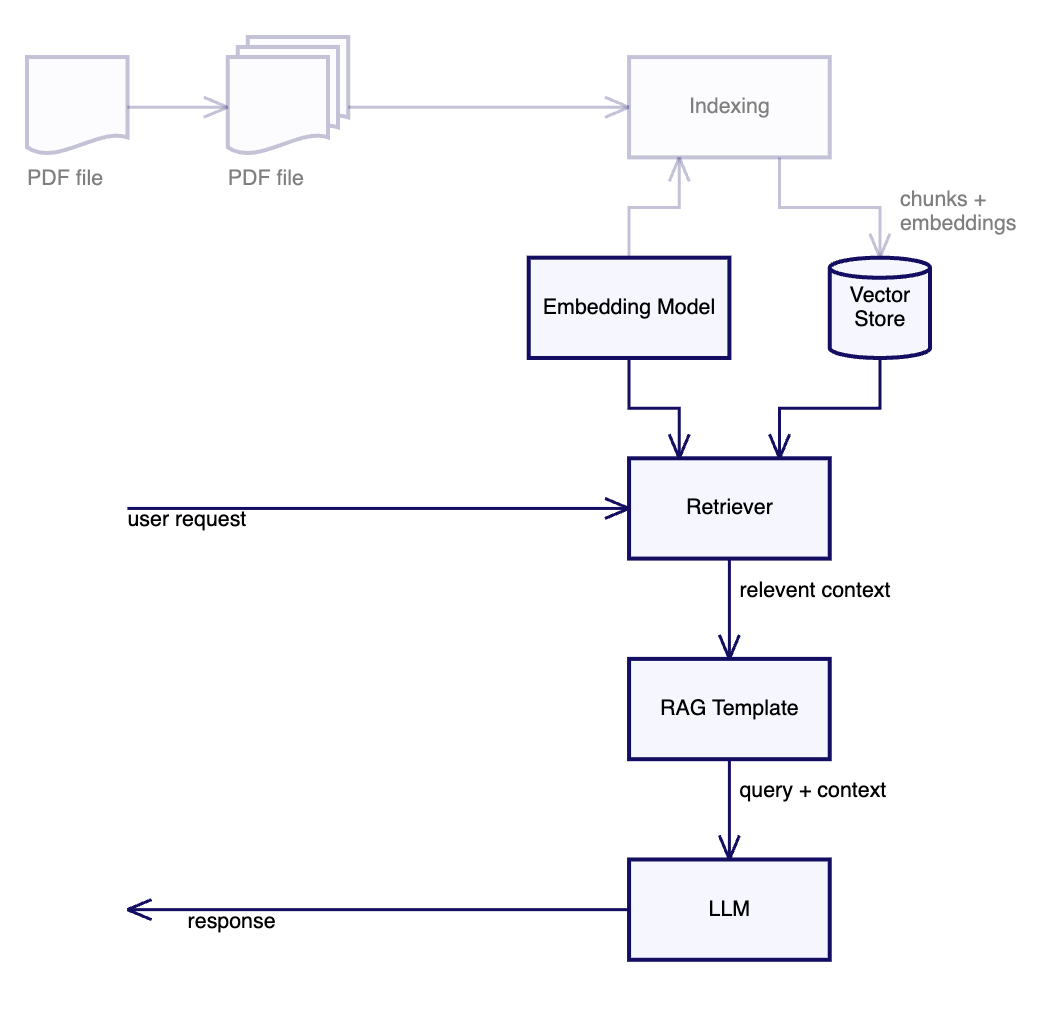
我们随后通过使用嵌入模型为查询创建嵌入来处理用户请求。我们使用该嵌入在向量存储上进行 ANN 相似度搜索以检索匹配片段。接下来,我们使用 RAG 提示模板将结果与原始查询结合,并将完整输入发送到 LLM。
CleanShot 2025-02-14 at 10.14.04@2x.png
使用场景 When to use
通过在其查询中提供相关信息的 LLM,RAG 克服了 LLM 只能根据其训练数据做出响应的限制。它结合了信息检索和生成模型的优点
RAG 特别适用于处理快速变化的数据,如新闻文章、股票价格或医学研究。它可以快速检索最新信息并将其整合到 LLM 的回复中,提供更准确和上下文相关的答案。
RAG 通过访问和整合知识库中的相关信息,增强了 LLM 回复的真实性,最大限度地降低了幻觉或虚构内容的风险。LLM 很容易将其作为背景的一部分引用所提供的文档,使用户能够验证其分析。
提供的检索文档的上下文可以减轻训练数据中的偏差。此外,RAG 可以通过在检索内容中嵌入特定任务的示例或模式来利用情境学习(ICL),使模型能够动态适应新任务或查询。
RAG 实践
我们的描述是我们认为的基本 RAG,与原始论文中描述的大致相同。我们在多个项目中使用了 RAG,发现它是使用 LLMs 与大量混乱的数据集交互的有效方式。然而,我们也发现需要对基本想法进行许多改进,以便使其能够解决严重问题。
示例 Example
我们将重点介绍的一个例子是为一家跨国生命科学公司构建查询系统的工作。该公司的研究人员经常需要调查各种化合物和物种过去研究的细节。这些研究跨越了二十年的研究,产生了 17,000 份报告,每份报告都有数千页,包含文本和表格数据。我们构建了一个聊天机器人,允许研究人员查询这些零散结构化的数据宝库。
在此项目之前,回答复杂问题通常需要手动筛选大量 PDF 文档,这可能需要几天到几周的时间。现在,研究人员可以利用我们的聊天机器人中的多跳查询,只需几分钟就能找到他们所需的信息。我们还在必要时加入了可视化,以简化对报告中使用的数据集的探索。
这是一个 RAG 成功应用的例子,但要将其从概念验证转变为可行的生产应用,我们需要克服几个严重的限制。
局限性 Limitation
| Limitation 局限性 | Explaintion 解释 | Mitigating Pattern 缓解模式 |
|---|---|---|
| Inefficient retrieval 效率低下检索 | 当你刚开始使用检索系统时,意识到仅仅依赖向量存储中的文档块嵌入并不能导致高效的检索,这会让人感到震惊。常见的假设是,仅凭块嵌入就能工作,但事实上,它虽然有用,但单独使用并不非常有效。当我们为文档块创建单个嵌入向量时,我们将多个段落压缩成一个密集向量。虽然密集嵌入在寻找相似段落方面做得很好,但它们不可避免地会丢失一些语义细节。无论进行多少微调,都无法完全弥合这一差距。 | Hybrid Retriever 混合检索器 |
| Minimalistic user query 简约用户查询 | 不是所有用户都能清楚地表达他们的意图,在结构良好的自然语言查询中。通常,查询简短且含糊不清,缺乏检索最相关文档所需的具体性。没有明确的关键词或上下文,检索器可能会拉入广泛的信息范围,包括不相关的内容,这导致结果不够准确且过于泛化。 | Query Rewriting 查询重写 |
| Context bloat 上下文膨胀 | Lost in the Middle 论文揭示,LLMs 目前难以有效利用长输入上下文中的信息。当相关细节位于上下文开头或结尾时,性能通常最强。然而,当模型必须从长输入的中间检索关键信息时,性能会大幅下降。即使在为大型上下文专门设计的模型中,这种限制仍然存在。 | Reranker 重排器 |
| Gullibility 易受骗 | 我们之前将 LLMs 描述为一个初级研究员:口才好,知识渊博,但对具体细节了解不深。还有一个形容词我们应该使用:轻信。我们的 AI 研究人员很容易被说服说出最好保持沉默的话,泄露秘密,或者编造事情以显得比实际更博学。 | Guardrails 护栏 |
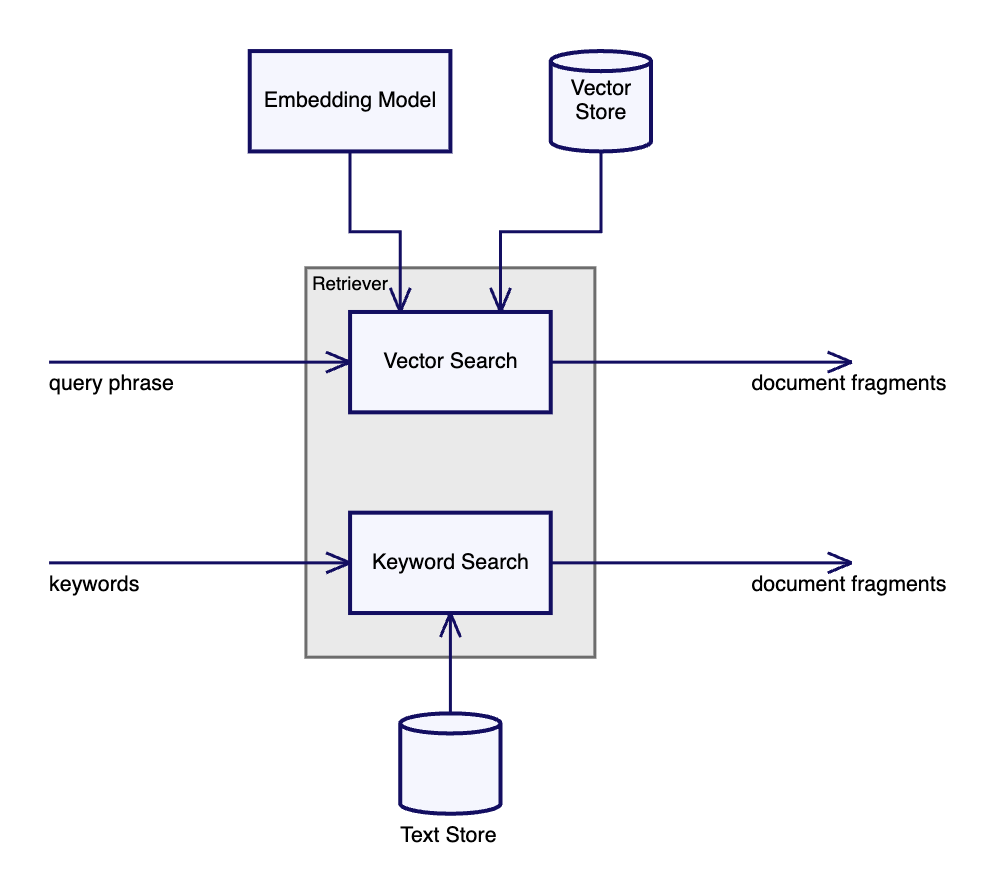
Hybrid Retriever 混合检索器
定义 Definition
Combine searches using embeddings with other search techniques(结合嵌入和其他搜索技术进行搜索)
CleanShot 2025-02-14 at 10.21.18@2x.png
尽管在文本嵌入上进行向量操作是一种强大而复杂的技巧,但简单的关键词搜索也有很多可说的。
TF/IDF 和 BM25 等技术是高效匹配精确术语的成熟方法。我们可以使用它们在大型文档集中进行更快、计算量更少的搜索,找到向量搜索本身无法揭示的候选者。将这些候选者与向量搜索的结果相结合,可以得到更好的候选者集。
缺点是这可能导致 LLM 的文档集过于庞大,但可以通过使用重新排序器来解决这个问题。
我们使用混合检索器时,我们需要补充索引过程,以准备我们的数据以进行向量搜索。我们尝试了不同的块大小,并最终选择了 1000 个字符,重叠 100 个字符。
这使得我们能够将 LLM 的注意力集中在最相关的上下文片段上。虽然模型上下文长度在增加,但当前研究表明,随着提示的增大,准确性会降低。
使用场景 When to use
嵌入是查找非结构化数据块的有力方式。它们自然适合使用 LLMs,因为它们在 LLM 中本身起着重要作用。但数据往往具有允许使用替代搜索方法的特征,这些方法可以作为补充使用。
确实,有时在检索器中我们根本不需要使用向量搜索。
举一个示例,我们使用 AI 来帮助理解遗留代码,我们使用了 Neo4J 图数据库来存储代码库的抽象语法树表示,并使用从文档和其他来源获取的数据注释了该树的节点。在我们的实验中,我们发现将模块的依赖关系、函数调用和调用者关系表示为图比使用嵌入更直接、更有效。
尽管如此,嵌入仍然在这里发挥了作用,我们在摄取过程中使用它们与 LLM 一起将文档片段放置在图节点上。
这里的关键点是,存储在向量数据库中的嵌入只是检索器可以操作的一种知识库形式。虽然对非结构化文本进行分块很有用,但我们发现,尽可能提取结构,并利用这种结构来支持和改进检索器是有益的。每个问题都有不同的最佳方式来组织数据以实现高效检索,我们发现使用多种方法获取有价值的文档片段进行后续处理是最好的。
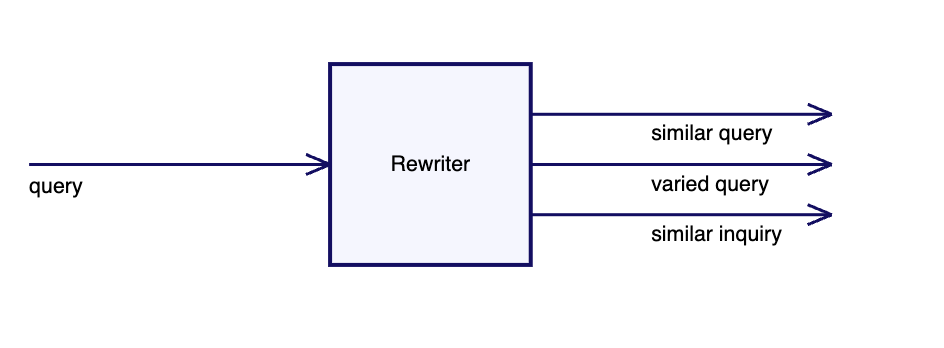
Query Rewriting 查询重写
定义 Definition
Use an LLM to create several alternative formulations of a query and search with all the alternatives (使用 LLM 创建多个查询的替代方案并使用所有替代方案进行搜索)
CleanShot 2025-02-14 at 10.26.01@2x.png
用过搜索引擎的人都知道,尝试不同的搜索词组合通常是最好的方法来找到我们想要的东西。在使用 LLMs 时这一点更为明显,重新表述一个问题往往会导致得到截然不同的答案。
我们可以通过获取一个 LLM 来多次改写查询,并将每个查询发送进行向量搜索来利用这种行为。然后我们可以将结果组合起来放入 LLM 提示中(通常需要使用 Reranker 的帮助)。
示例 Example
在我们的生命科学示例中,用户可能从一个提示开始,探索成千上万的研究成果。
Were any of the following clinical findings observed in the study XYZ-1234? Piloerection, ataxia, eyes partially closed, and loose feces?
重写器将其发送到 LLM,要求其提出替代方案。
1. Can you provide details on the clinical symptoms reported in research XYZ-1234, including any occurrences of goosebumps, lack of coordination, semi-closed eyelids, or diarrhea?
2. In the results of experiment XYZ-1234, were there any recorded observations of hair standing on end, unsteady movement, eyes not fully open, or watery stools?
3. What were the clinical observations noted in trial XYZ-1234, particularly regarding the presence of hair bristling, impaired balance, partially shut eyes, or soft bowel movements?
最优备选方案数量因数据集而异:通常,3-5 个变体适用于多样化的数据集,而简单的数据集可能需要多达 3 次重写。在调整查询重写时,使用评估来跟踪进度。
使用场景
查询重写对于涉及多个子主题或专业关键词的复杂搜索至关重要,尤其是在特定领域的向量存储中。
创建几个替代查询可以提高我们能够找到的文档,但这需要额外的调用 LLM 来生成这些替代方案,以及额外的调用检索器来使用这些替代方案。这些额外的调用将产生资源成本并增加延迟。团队应该尝试确定检索改进是否值得这些成本。
在我们的生命科学合作示例中,我们发现使用 GPT 4o 创建五个变体是值得的。
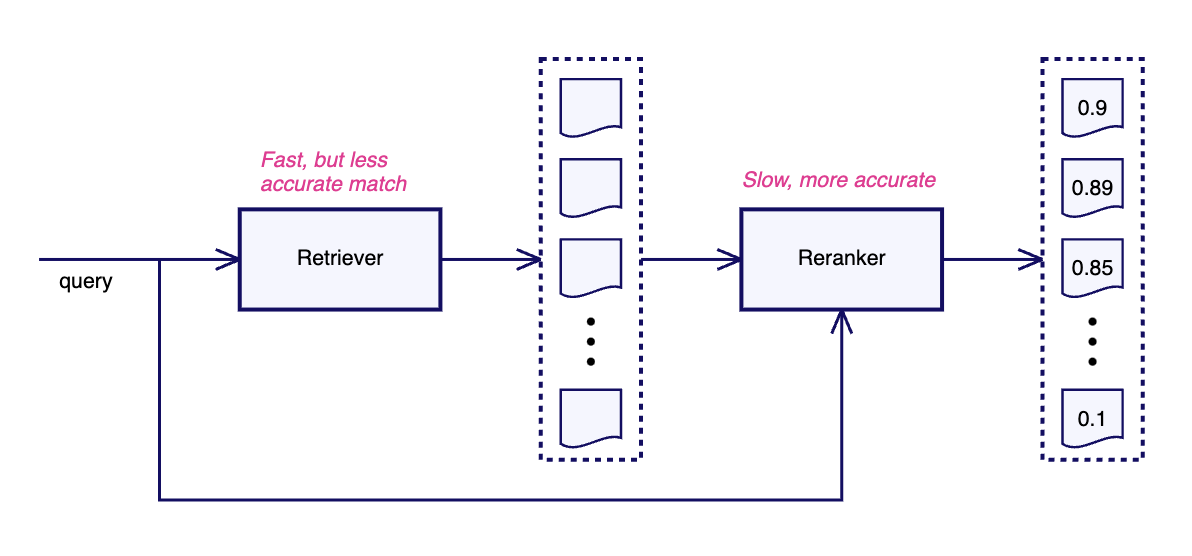
Reranker 重排器
定义 Definition
Rank a set of retrieved document fragments according to their usefulness and send the best of them to the LLM. (对检索到的文档片段按其有用性进行排序,并将最好的发送到 LLM。)
CleanShot 2025-02-14 at 10.28.58@2x.png
Retriever的任务是快速找到相关文档,但快速响应搜索会导致结果质量降低。我们可以尝试更复杂的搜索,但通常在整个数据集上执行复杂搜索需要太长时间。在这种情况下,我们可以快速生成大量质量参差不齐的文档,并根据它们的信息作为 LLM's 提示的上下文的相关性和有用性进行排序。
重排器可以使用深度神经网络模型,通常是像 bge-reranker-large 这样的交叉编码器,来准确地对检索到的文档集中与输入查询的相关性进行排序。这种重排过程在整个向量存储内容上执行太慢且成本高昂,但当只考虑由更快但更粗糙的搜索返回的候选者时,却是值得的。然后我们可以从这些候选者中选择最佳者放入提示中,这阻止了提示变得臃肿,并防止 LLM 被低质量文档所困惑。
使用场景 When to use
Reranking 提高了 RAG 系统中答案的准确性和相关性。当候选答案过多,或者低质量答案会降低 LLM's 的响应质量时,重排序是有价值的。
重排序确实涉及与另一个 AI 模型的额外交互,从而增加了响应的处理成本和延迟,这使得它们不太适合高流量应用。最终,选择是否重排序应基于 RAG 系统的具体要求,在高质量响应的需求与性能和成本限制之间进行平衡。