Deepseek的Native Sparse Attention方向
Introduction
长上下文建模作为下一代大型语言模型的关键能力,其重要性日益凸显,这得益于各种现实应用,包括深入推理、代码库级别的代码生成和多轮自主代理系统等.
然而, 随着序列长度的增加,vanilla Attention机制的高复杂性成 关键延迟瓶颈。
理论估计表明,注意力计算使用 softmax 架构在解码 64k 长度上下文时占总延迟的 70-80%,凸显了更高效注意力机制的迫切需求。
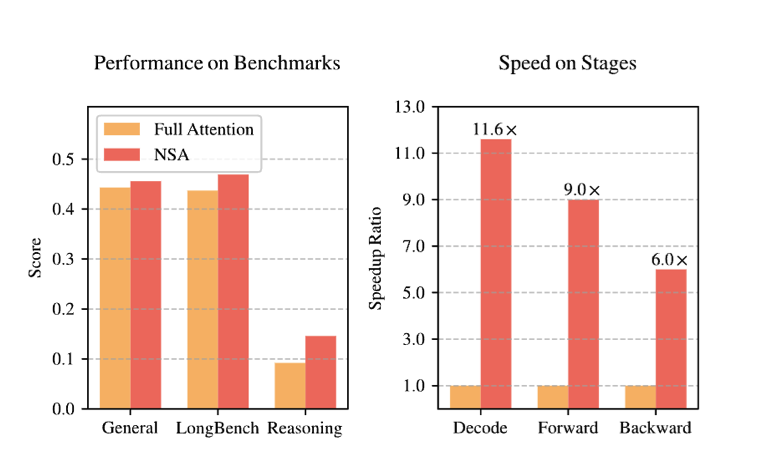
Figure 1 | Comparison of performance and efficiency between Full Attention model and NSA.
一种高效长上下文建模的自然方法是利用 softmax 注意力固有的稀疏性,通过选择性计算关键查询-键对可以显著减少计算开销,同时保持性能。最近的研究通过多种 策略展示了这种潜力:KV 缓存淘汰方法、分块 KV 缓存选择方法以及基于采样、聚类或哈希的选择方法。
尽管这些策略很有前景,但现有的稀疏注意力方法在 实际部署中往往不足。
为了解决这些限制,有效稀疏注意力的部署必须应对两个关键挑战:
- 硬件对齐的推理加速:将理论 计算减少转化为实际速度提升,需要在预填充和解码阶段进行硬件友好的算法设计,以减轻内存访问和 硬件调度瓶颈;
- 训练感知的算法设计:通过可训练算子实现端到端计算,以降低训练成本同时保持 模型性能。这些要求对于实现快速长上下文推理或训练的实际情况至关重要。在考虑这两个方面时,现有方法仍然存在明显的差距。
NSA(Native Sparse Attention)

Figure 2 | Overview of NSA’s architecture.
如图 2 所示,左侧:框架通过三个并行注意力分支处理输入序列:对于给定的查询,前向键和值被处理成压缩注意力以处理粗粒度模式,选择注意力以处理重要标记块以及滑动注意力以处理局部上下文。
右侧:每个分支产生的不同注意力模式的可视化。绿色区域表示需要计算注意力分数的区域,而白色区域表示可以跳过的区域。
NSA 通过将键和值组织成时间块并通过三个注意力路径进行处理来减少每个查询的计算量:压缩的粗粒度词素、选择性保留的细粒度词素以及用于局部上下文信息的滑动窗口。然后实现了专门的内核以最大化其实际效率.
NSA 引入了两种核心创新对应上述关键需求:
- 硬件对齐系统:优化块状稀疏注意力以实现 Tensor Core 利用和内存访问,确保平衡的算术强度。
- 训练感知设计:通过高效算法和反向操作实现稳定的端到端训练。此优化使 NSA 能够支持高效部署和端到端训练。
我们通过在真实世界语言语料库上的综合实验评估 NSA。在 27B 参数的 transformer 骨干上预训练, 使用 260B 个标记,我们评估了 NSA 在通用语言评估、长上下文评估和思维链推理评估中的性能。
我们还比较了在 A100 GPU 上使用优化后的 Triton(Tillet 等人,2019)实现时的内核速度。实验结果表明,NSA 在实现与全注意力基线相当或更优性能的同时,优于现有的稀疏注意力方法。
此外,与全注意力相比,NSA 在解码、正向和反向阶段提供了显著的加速,对于更长的序列,加速比还会增加。这些结 果验证了我们的分层稀疏注意力设计有效地平衡了模型能力和计算效率。
Rethinking Sparse Attention Methods
现代稀疏注意力方法在降低 Transformer 模型的理论计算复杂度方面取得了显著进展。然而,大多数方法主要在推理过程中应用稀疏性,同时保留预训练的全注意力骨干,这可能会引入架构偏差,限制其充分利用稀疏注意力优势的能力。
我们通过两个关键视角系统地分析了这些局限性。
The Illusion of Efficient Inference (高效推理的幻觉)
尽管在注意力计算中实现了稀疏性,许多方法未能实现相应的推理延迟降低,主要由于两个挑战:
Phase-Restricted Sparsity.
例如,H2O等方法应用稀疏性,在自回归解码过程中,需要计算密集型的预处理(例如,注意力图计算、索引构建)以进行预填充。相比 之下,MInference等方法仅关注预填充稀疏性。这些方法未能实现所有推理阶段的加速,因为至少有一个阶段计算成本与全注意力相当。阶段专业化降低了这些方法在以预填充为主的工作负 载(如书籍摘要和代码补全)或以解码为主的工作负载(如长思维链推理)中的加速能 力。
Incompatibility with Advanced Attention Architecture.
无法适应现代解码高效架构,如 Mulitiple-Query Attention (MQA)和 GroupedQuery Attention (GQA),这些架构通过在多个查询头之间共享 KV 来显著减少了解码过程中的内存访问瓶颈。
例如,在 Quest等方法中,每个注意力头独立选择其 KV-cache 子集。尽管它在多头注意力(MHA)模型中展示了持续的计算稀疏性和内存访问稀疏性,但在基于 GQA 等架构的模型中,KV-cache 的内存访问量对应于同一 GQA 组内所有查询头选择的并集。这种架构特性意味着,虽然这些方法可以减少计算操作,但所需的 KV-cache 内存访问仍然相对较高。这种限制迫使做出一个关键选择:虽然一些稀疏注意力方法减少了计算,但它们的分散内存访问模 式与高级架构的效率内存访问设计相冲突。
这些限制产生的原因是许多现有的稀疏注意力方法专注于 KV 缓存减少或理论计算减少,但在高级框架 或后端中难以实现显著的延迟减少。这促使我们开发结合先进架构和硬件高效实现的算法,以充分利用稀疏性来提高模型效率。
The Myth of Trainable Sparsity(可训练稀疏的神话)
我们追求原生可训练稀疏注意力的动机源于分析仅推理方法的两项关键洞察:
- 性能下降. 事后应用稀疏性迫使模型偏离其预训练优化轨迹。正如 Chen 等人(2024 年)所证明的,前 20%的注意力只能覆盖70%的总注意力分数,使得预训练模型中的检索头等结构在推理过程中容易受到剪枝的影响。
- 训练效率需求. 高效处理长序列训练对于现代LLM开发至关重要。这包括在更长的文档上进行预训练以增强模型容量,以及随后的适应阶段,如长上下文微调和强化学习。
然而,现有的稀疏注意力方法主要针对推理,对训练中的计算挑战基本未予解决。这种限制阻碍了通过高效训练开发更强大的长上下文模型。此外,尝试将现有稀疏注意力适应于训练也暴露出挑战:
Non-Trainable Components
在 ClusterKV(包括 k-means 聚类)和 MagicPIG(包括基于 SimHash 的选择)等方法中的离散操作在计算图中产生不连续性。这些不可训练组件阻止梯度通过标记选择过程流动,限制了模型学习最优稀疏模式的能力。
Inefficient Back-propagation
一些理论上可训练的稀疏注意力方法在实际训练中存在效率低下的问题。在方法中使用令牌粒度选择策略在 HashAttention等方法中使用,导致在注意力计算期间需要从 KV 缓存中加载大量单个标记。这种非连续内存访问阻止了 FlashAttention 等快速注意力技术的有效 适应,这些技术依赖于连续内存访问和块级计算以实现高吞吐量。因此,实现被迫回退到低硬件利用率,显著降低训练效率。
Native Sparsity as an Imperative(本地稀疏性作为一项强制性要求)
这些在推理效率和训练可行性方面的限制激励我们对稀疏注意力机制进行根本性重新设计。我们提出了 NSA,一个原生的稀疏注意力框架,该框架解决了计算效率和训练需求。
Algorithm Design
Token Compression
通过将连续的键或值块聚合到块级表示中,我们获得了捕获整个块信息的压缩键和值。压缩表示捕获更粗粒度的更高层语义信息,并减少注意力的计算负担。
Token Selection
仅使用压缩键,值可能会丢失重要的细粒度信息,这促使我们选择性地保留个别键和值。以下我们描述了我们的高效令牌选择机制,该机制以低计算开销识别并保留最相关的令牌。
Blockwise Selection
我们的选择策略在空间连续块中处理键和值序列,受两个关键因素的驱动:硬件效率考虑和注意力分数的内在分布模式。
为了实现分块选择,我们首先将键值序列划分为选择块。为了确定对注意力计算最重要的块,我们需要为每个块分配重要性分数。
Importance Score Computation
计算计算块的重要性得分可能会引入显著开销。幸运的是,压缩令牌的注意力计算产生 了中间注意力得分,我们可以利用这些得分来诱导选择块的重要性得分
Top-𝑛 Block Selection
在获得选择块重要性分数后,我们保留按块重要性分数排名的前 n 个稀疏块中的标记
Sliding Window
在注意力机制中,局部模式通常适应得更快,可能会主导学习过程,从而阻止模型有效地从压缩和选择 标记中学习。为了解决这个问题,我们引入了一个专门的滑动窗口分支,该分支明确处理局部上下文, 允许其他分支(压缩和选择)专注于学习它们各自的特征,而不会被局部模式所限制。
具体来说,我们在窗口中维护最近的标记,并将不同信息源(压缩标记、选择标记、滑动窗口)的注意力计算隔离到不同的分支中。然后通过一个学习到的门控机制对这些分支输出进行聚合。
为了进一步防止在注意力分支之间发生具有边际计算开销的简接学习,我们为三个分支提供了独立的关键字和 值。这种架构设计通过防止局部和长距离模式识别之间的梯度干扰,实现了稳定的通过引入最小开销的学习。
Kernel Design
为了在训练和预填充期间实现 FlashAttention 级别的加速,我们在 Triton 上实现了硬件对齐的稀疏注意力内核。
鉴于 MHA 内存密集且对解码效率低下,我们关注具有共享 KV 缓存的架构,如 GQA 和 MQA,这些架构遵循当前最先进的LLMs。
虽然压缩和滑动窗口注意力计算与现有的 FlashAttention-2 内核兼容,但我们引入了专门的核心设计用于稀疏选择注意力。如果我们遵循 FlashAttention 将时间连续的查询块加载到 SRAM 的策略,由于块内的查询可能需要不连续的 KV 块,这将导致内存访问效率低 下。
为了解决这个问题,我们的关键优化在于不同的查询分组策略:对于查询序列中的每个位置,我们将 GQA 组内的所有查询头(它们共享相同的稀疏 KV 块)加载到 SRAM 中。
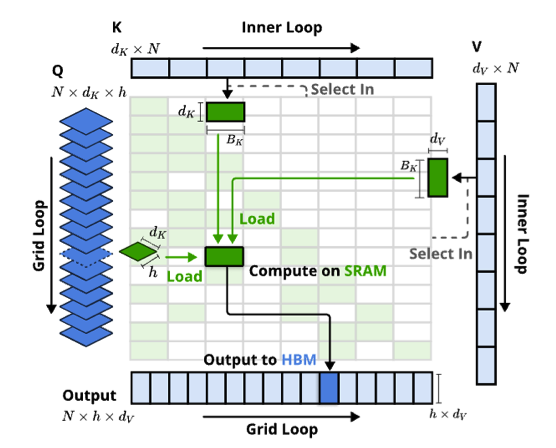
Figure 3 | Kernel design for NSA.
图 3 说明了我们的正向传递实现。内核通过 GQA 组(网格循环)加载查询,获取相应的稀疏 KV 块(内部循 环),并在 SRAM 上执行注意力计算。 绿色块表示 SRAM 上的数据,而蓝色表示 HBM 上的数据。
所提出的内核架构具有以下关键特性:
- Group-Centric Data Loading.
- Shared KV Fetching.
- Outer Loop on Grid.
本设计通过 1. 分组共享消除冗余的 KV 传输,以及 2. 平衡 GPU 流式多处理器的计算工作负载,实现了接近最优的算术强度。
Performance Comparison
General Evaluation
总体评估。我们对预训练的 NSA 和全注意力基线进行了评估,评估范围涵盖知识、推理和编码能力的一 系列基准,包括 MMLU、MMLU-PRO、 CMMLU、BBH、GSM8K、MATH、DROP(、MBPP和 HumanEval。结果如表 1 所示。
Table 1 | Pretraining performance comparison between the full attention baseline and NSA on general benchmarks
尽管 NSA 稀疏,但整体性能优越,在 9 项指标中有 7 项超过了所有基线,包括全注意力。这表明,尽管 NSA 可能无法充分利用 其在较短序列上的效率优势,但表现出强大的性能。
值得注意的是,NSA 在推理相关基准(DROP: +0.042,GSM8K:+0.034)上取得了显著提升,这表明我们的预训练有助于模型发展专门的注意力机制。这种稀疏注意力预训练机制迫使模型关注最重要的信息,可能通过过滤掉无关注意力路径的噪声提高性能。 该系统在多种评估中的稳定表现也验证了 NSA 作为通用架构的鲁棒性。
Long-Context Evaluation
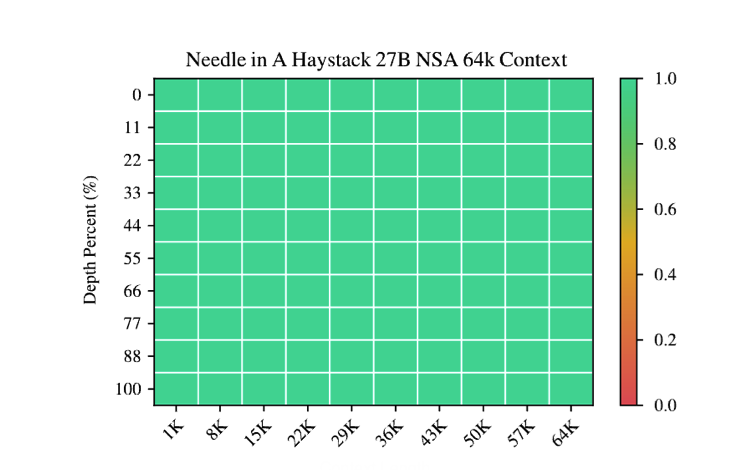
Figure 5 | Needle-in-a-Haystack retrieval accuracy across context positions with 64k context length.
如图 5 所示,在 64k 上下文“大海捞针”(Kamradt,2023)测试中,NSA 在所有位置上实现了完美的检索准确率。这种性能源于我们设计的分层稀疏注意力,它结合了压缩标记以实现高效的上下文扫描和选择标记以进行精确的局部信息检索。粗粒度压缩以低计算成本识别相关上下文块,而所选标记的标记级注意力确保了关键细粒度信息的保留。这种设计使 NSA 能够同时保持全局意识和局部精度。
我们还在 LongBench(白等,2023)上评估了 NSA 与最先进的稀疏注意力方法和全注意力基线。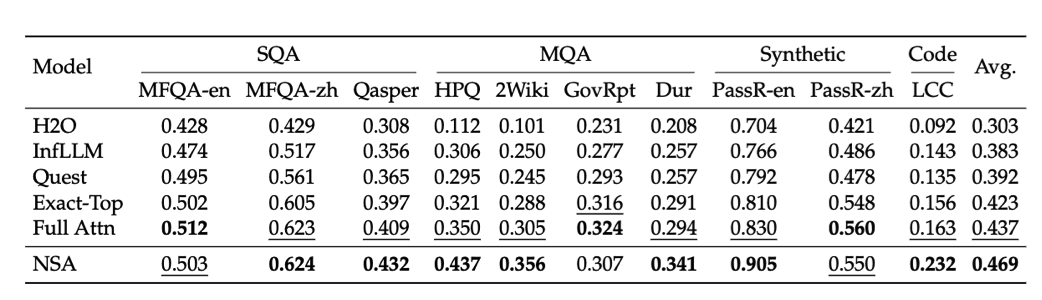
Table 2 | Performance comparison between our NSA and baselines on LongBench, including subsets in single document QA, multi-document QA, synthetic and code task categories. NSA outperformed most of the baselines including Full Attention.
如表 2 所示,NSA 实现 了最高的平均分数 0.469,优于所有基线(比全注意力高 0.032,比 Exact-Top 高 0.046)。
这种改进源于两个关键创新:
- 我们本地的稀疏注意力设计,使稀疏模式在预训练期间实现端到端优化,促进了稀疏注意力模块与其他模型组件之间的同步适应;
- 分层稀疏注意力机制在局部和全局信息处理之 间取得平衡。
值得注意的是,NSA 在需要长上下文复杂推理的任务上表现出色,在多跳问答任务(HPQ 和 2Wiki) 上相对于全注意力机制分别提升了+0.087 和+0.051,在代码理解(LCC:+0.069)方面超过了基线, 并在段落检索(PassR-en:+0.075)上优于其他方法。
这些结果验证了 NSA 处理各种长上下文挑战的能力,其原生预训练的稀疏注意力在学习任务最优模式时提供了额外的优势。
Chain-of-Thought Reasoning Evaluation
为了评估 NSA 与先进下游训练范式的兼容性,我们研究其通过后训练获取思维链数学 推理能力的能力。
鉴于强化学习在较小规模模型上的有限有效性,我们采用 DeepSeek-R1 的知识蒸馏, 使用 32k 长度的 10B 数学推理轨迹进行监督微调(SFT)。这产生了两个可比较的模型:全注意力-R (全注意力基线)和 NSA-R(我们的稀疏变体)。
为了验证推理深度的影响,我们进行了两个生成上下文限制的实验:8k 和 16k 个标记,测量扩 展推理链是否提高准确性。
Table 3 | AIME Instruction-based Evaluating after supervised fine-tuning.
如表 3 所示,在 8k 上下文设置下,NSA-R 比 Full Attention-R 实现了显著更高的准确率 (+0.075),这种优势在 16k 上下文中仍然存在(+0.054)。
这些结果验证了原生稀疏注意力两个关键优势:
- 预训练的稀疏注意力模式能够高效捕捉对复杂数学推导至关重要的长距离逻辑依赖
- 我们架构的硬件对齐设计保持了足够的内容密度,以支持不断增长的推理深度而不会出现灾难性遗忘。在 上下文长度上的持续出色表现证实了,当原生集成到训练流程中时,稀疏注意力对于高级推理任务的有效性。
Efficiency Analysis
我们评估了在 8-GPU A100 系统上 NSA 与全注意力机制的计算效率。
Training Speed
我们将我们的基于 Triton 的 NSA 注意力机制和全注意力与基于 Triton 的 FlashAttention-2 进行比较, 以确保在相同后端上公平的速度比较。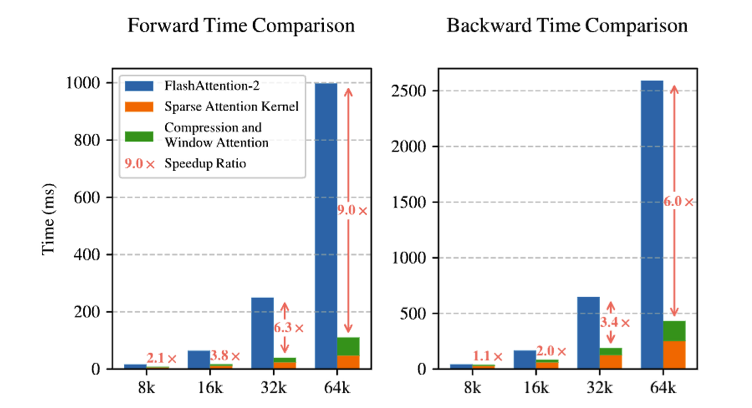
Figure 6 | Comparison of Triton-based NSA kernel with Triton-based FlashAttention-2 kernel.
如图 6 所示,随着上下文长度的增加,我们的 NSA 实现了逐步加 速,在 64k 上下文长度下,实现了 9.0 倍的向前加速和 6.0 倍的向后加速。值得注意的是,随着序列长度 的增加,速度优势变得更加明显。这种加速源于我们硬件对齐的算法设计以最大化稀疏注意力架构的效率:(1) 块状内存访问模式通过合并加载最大化Tensor Core利用率,(2) 内核中的精细循环调度消除了冗余的 KV 传输。
Decoding Speed
注意力的解码速度主要取决于内存访问瓶颈,这与 KV 缓存加载量密切相关。在每一步解码中,我们的 NSA 只需加载最多压缩标记.
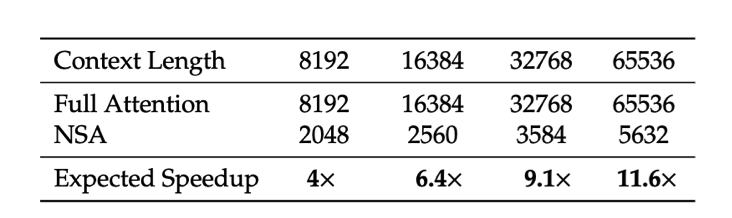
Table 4 | Memory access volume (in equivalent number of tokens) per attention operation during decoding.
如表 4 所示,随着解码长度的增加,我们的方法在延迟方面表现出显著降低,在 64k 上下文长度下实现了高达 11.6 倍的速度提升。这种在内存访问效率方面的优势也随着序列长度的增加而增强。
Source of inspiration
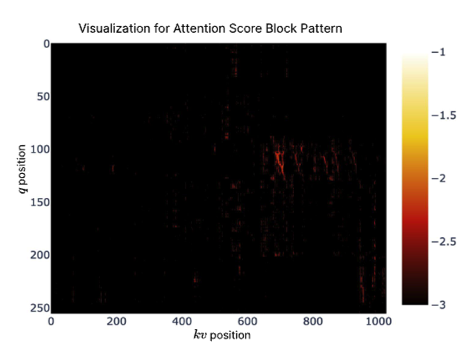
Figure 8 | Visualization of Attention Map on a Full Attention transformer.
浅色区域表示更高的注意力值。如图所示,注意力分数呈现块状聚类分布。
为了探索变压器注意力分布中的潜在模式并为我们的设计寻求灵感,我们在图 8 中可视化了预训练的 27B 全注意力模型的注意力图。
可视化揭示了有趣的模式,其中注意力分数往往表现出块状聚类特征,附近的键通常显示出相似的关注度分数。
这一观察启发了我们的设计,即基于空间连续性选择关键块可能是一种 有希望的方法。块状聚类现象表明,序列中相邻的标记可能与查询标记共享某些语义关系,
尽管这些关系 的确切性质需要进一步研究。这一观察激励我们探索一种稀疏注意力机制,该机制在连续标记块上而不是 单个标记上操作,旨在提高计算效率并保留高注意力模式。