网络IO
引导
网络 IO 是我们理解计算机网络中数据流动的基础,首先在了解不同的网络 IO 的模型之前,我们应该先对数据如何流动的有一个比较清晰的认知,我们用一个图例来展示数据是如何流转的。

IO 实际上是请求很基础的一部分,有读取请求数据,写入响应数据,也有一些硬盘 IO, 和向其他应用服务器的调用。
for conn in open_connections:
read(conn)
大部分网络网络代码示例可能长得像上面一样。 默认情况下,read 系统调用会阻塞,如果连接建立后,没有写入任何的数据,我们的程序就会卡住等待,无法为其他的连接响应。所以我们需要一种方法来处理长时间的 IO 请求。
很幸运,我们有五种 IO 的处理方式,接下来一一进行介绍。
阻塞 (BLOCKING)
系统调用在数据到达并被复制到我们的应用程序之前不会返回,在多线程环境中还算可行,即使一些线程被阻塞,我们还有一些线程可以提供服务。

非阻塞 (NONBLOCKING)
如果数据不可用,系统调用可以立即返回 EWOULDBLOCK ,而不是阻塞。
我可以遍历所有的连接,如果没有数据可用,那么我们就轮询连接,消耗 CPU.

IO 多路复用 (I/O MULTIPLEXING)
一次不只处理一个文件描述符,所有我们需要一种方式来监视多个文件描述符的变化。 (SELECT/POLL/EPOLL/KQUEUE) 只是用于此种监视方式的不同方法

SELECT
select 允许您传入文件描述符列表,并返回每个 FD 的状态。它有一些相当大的性能限制。每次调用 select 时都需要把整个文件描述符集合从用户态复制到内核态,这在文件描述符数量较多时会导致性能问题。文件描述符数量 (1024) 受限。
POLL
Poll 与 select 类似,但它使用一个 pollfd 的结构体数组来存储文件描述符集合。每个结构体记录单个文件描述符及其期望的事件和实际发生的事件。 当监视的文件描述符很多时,性能不如 epoll,因为它需要遍历整个数组来检查状态变化。 与 select 类似,每次调用 poll 也需要复制整个文件描述符数组到内核态。
EPOLL
Epoll 是 Linux 特有的 IO 多路复用技术,它通过创建一个 epoll 实例来管理多个文件描述符。使用 epollctl 添加、修改或删除文件描述符的监听事件,而 epollwait 则用来等待事件的发生。
KQUEUE
Kqueue 是 BSD 系统中的 IO 多路复用技术,它使用事件过滤器来监视各种事件(包括文件描述符事件和其他类型的事件)。
Here’s a more in depth comparison of select / poll / epoll
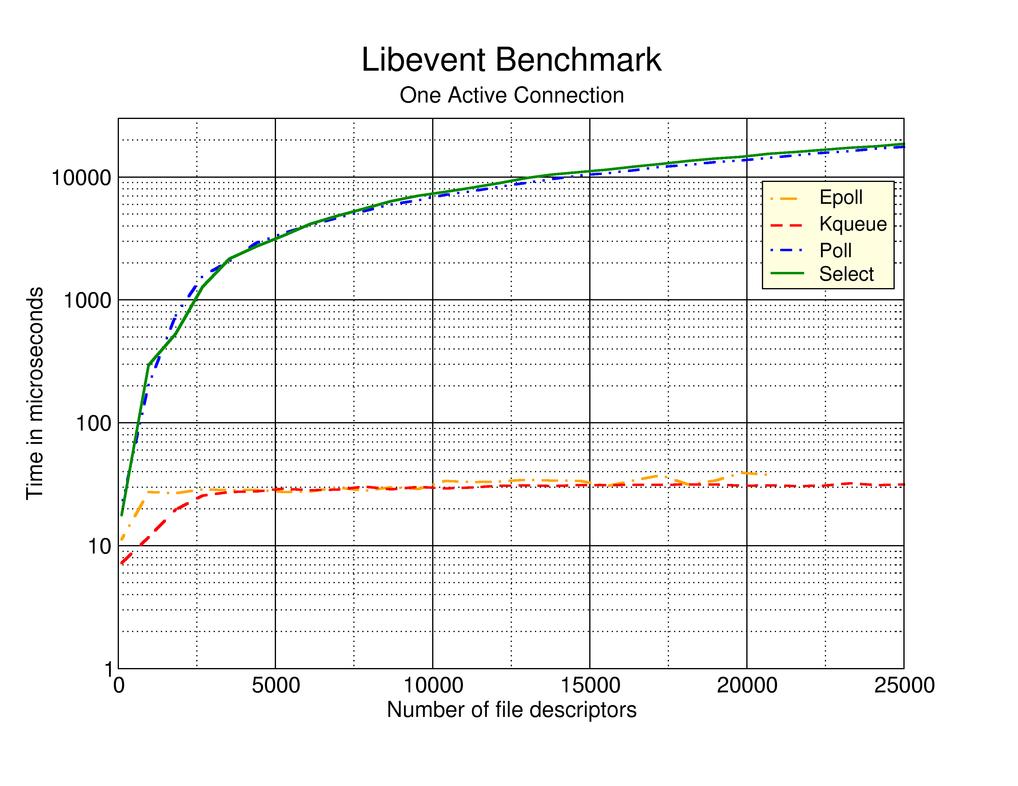
性能对比图
信号 (SIGNALS)
不是通过检查文件描述符的状态,我们可以要求内核在数据可用时发送信号。
虽然信号驱动 I/O 为某些应用提供了方便,特别是在低负载下的简单应用中,但它在高性能和高并发的环境下通常不是首选。信号处理在多线程环境中可能会引起问题,因为信号处理通常是中断当前进程执行的,这可能导致竞争条件和其他并发问题。
异步 IO (AIO)
应用程序发起 I/O 操作,并在操作完成时收到通知(通过信号)。类似于 SIGIO,不同之处在于数据一旦移动到应用程序缓冲区后就会通知应用程序。
POSIX AIO
POSIX 异步 I/O 通过libaio库提供,在 Linux 系统中,这种方式主要适用于磁盘文件,而对于网络套接字,这种支持并不是很好。尽管技术上可能通过某些 hack 手段实现,但在生产环境中,POSIX AIO 并不被推荐用于网络 I/O。
IO_URING
Linux 5.1 及以后版本引入了io_uring接口,这是一种新的高性能异步 I/O 框架,它设计用来克服传统 Linux AIO 接口的限制。io_uring支持文件和套接字的异步操作,提供了比传统方法更高的效率和更低的 CPU 开销。
io_uring通过一种环形队列的机制来提交和完成 I/O 请求,这种机制非常适合于高吞吐量的 I/O 操作。它允许用户空间应用直接与内核空间交互,减少了系统调用的次数和相关开销。
汇总
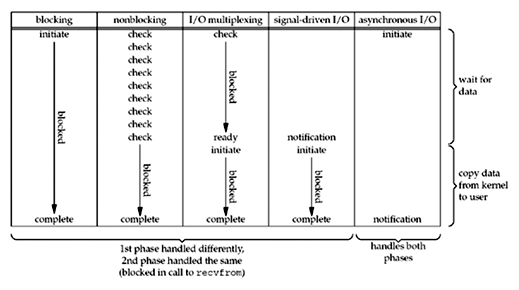
Unix 网络编程中 IO 模型的比较