高级RAG
RAG
Retrieval Augmented Generation (检索增强生成) 从数据源检索的信息,大模型以此为基础生成回答
RAG 基本概念
作用一言以蔽之,如何从大量的数据集中快速获取到我们需要的准确的数据。
Retrieval
检索是从存储位置获取或检索数据或信息的过程。在数据库或搜索引擎的背景下,它是指根据特定查询检索相关数据的过程。
Vector Similarity Search
向量相似性搜索,向量相似性搜索涉及比较向量(数字列表)以确定它们的相似程度。它通常用于机器学习和人工智能,根据给定的输入在数据库中找到最相似的项目。
Vector Database
向量数据库,设计用来存储矢量的数据库,通常与机器学习模型一起使用。这些数据库针对矢量相似性搜索进行了优化。
Chunking
分块,这是将输入数据(如文本)进行分割成更小、可管理的块或“块”的过程。这可以使处理更有效,特别是在自然语言处理等情境中,其中输入可能非常长。
Embeddings / Vectors
嵌入/向量,在机器学习中,嵌入指的是将离散项目(如单词或产品)转换为连续向量。这些向量以一种能够被算法处理的方式捕捉项目之间的语义含义或关系。
K Nearest Neighbors (KNN)
K 最近邻居(KNN),这是一种用于分类和回归的算法类型。给定一个输入,KNN 找到距离该输入最近的'k'个训练样本,并根据它们的值或标签做出决定。

标准RAG

- 将文本分割成小块,
- 然后使用某种 Transformer Encoder 模型将这些小块转换为向量,
- 把这些向量汇总到一个索引中,最后创建一个针对大语言模型的提示,指导模型根据我们在搜索步骤中找到的上下文回答用户的查询。
- 我们用相同的 Encoder 模型将用户的查询转化为向量,
- 然后对这个查询向量进行搜索,与索引进行匹配,找出最相关的前 k 个结果,
- 从我们的数据库中提取相应的文本块,并将其作为上下文输入 LLM 进行处理。
Retriever
在 RAG-LLM设置中,检索器能够捕捉查询和文档之间更复杂的语义关系,从而导致更准确的检索结果。检索器可以将文档和查询嵌入到高维向量空间中,向量之间的距离对应于文档与查询的相关性。与输入查询不太相关的文档将具有较大的“距离”,因此应当被视作不相关而忽略。
检索器接收输入的查询,使用查询编码器将其转换为矢量,然后在语料库中找到最相似的文档矢量。然后将与这些矢量相关联的文档传递给生成器。
在检索过程中需要考虑的一个重要方面是检索到的文档的准确性。检索准确性通常可以用距离度量来量化,例如在机器学习模型的背景下使用向量相似度。本质上,与输入查询无关的文档将展现出与查询向量更大的“距离”,表明它们的不相关性。这个距离作为一个指标,用于确定与查询相关的文档。
Generator
在 RAG-LLM设置中,生成器是一个大型的Transform转换器模型,比如 GPT3.5,GPT4,Llama2,Falcon,PaLM 和 BERT。生成器接受输入查询和检索到的文档,并生成响应。
检索到的文档和输入的查询被连接在一起,并输入到生成器中。然后生成器使用这个组合的输入来生成一个响应,检索到的文档提供额外的上下文和信息,帮助生成器产生更加明智和准确的响应,减少幻觉。
高级RAG
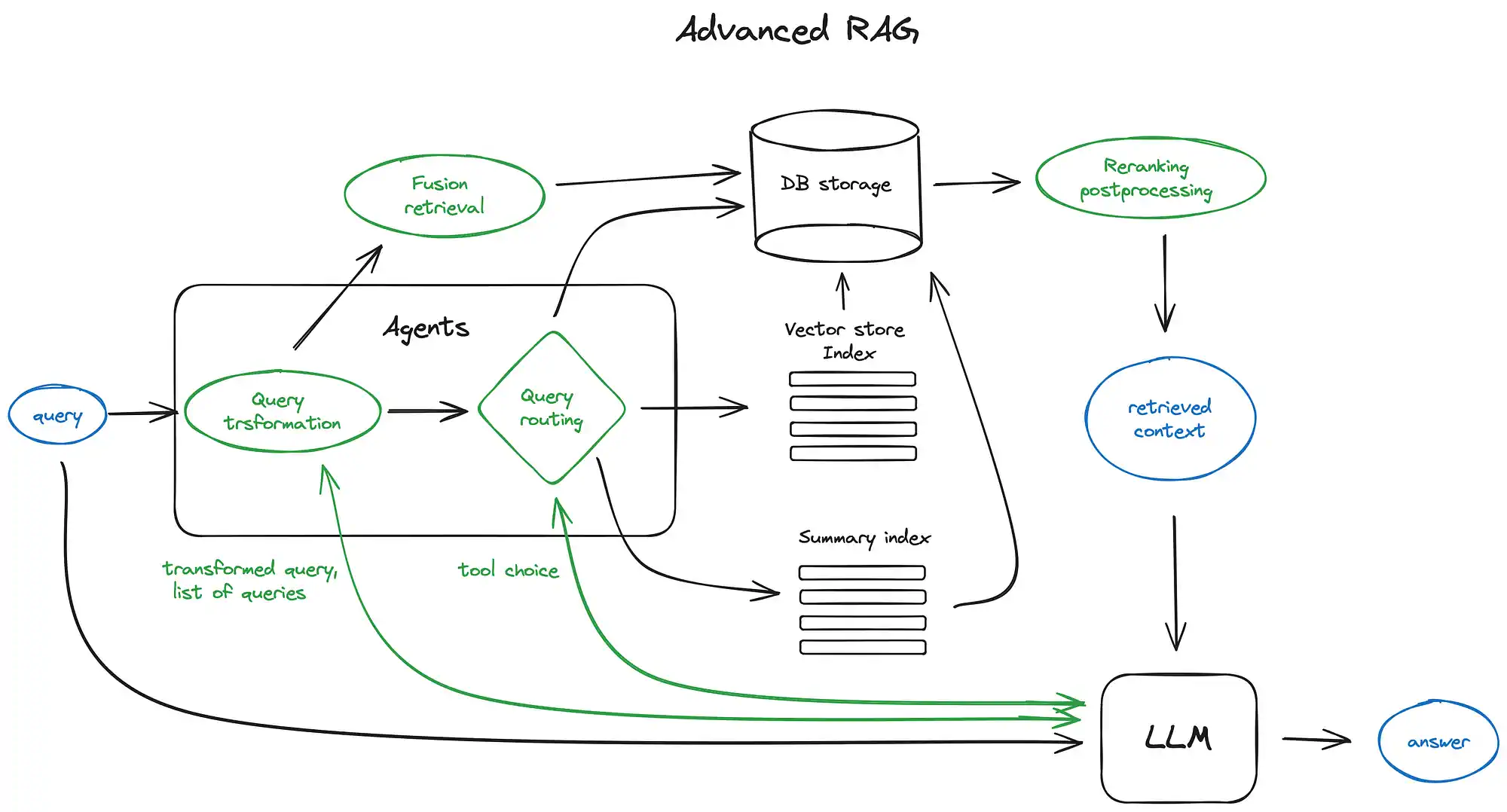
图中的绿色元素代表我们将进一步探讨的核心 RAG 技术,蓝色部分则是相关文本。
Query Transformation 查询变换
查询变换是利用大语言模型作为推理引擎,对用户输入进行调整的一系列技术,目的是提升检索的质量。
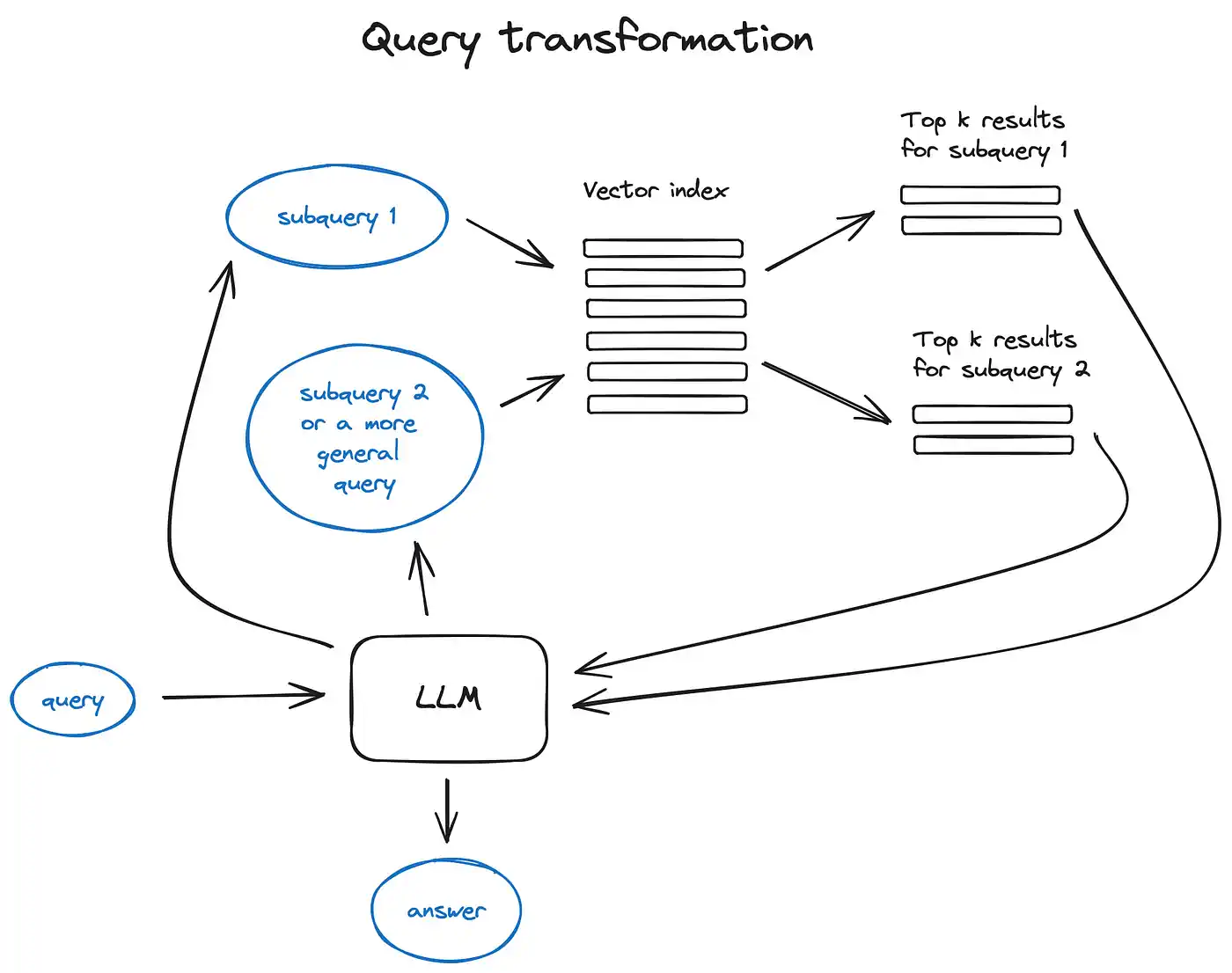
对于复杂的查询,大语言模型能够将其拆分为多个子查询。
比如,当你问:
— “在 Github 上,Langchain 和 LlamaIndex 这两个框架哪个更受欢迎?”,
我们不太可能直接在语料库的文本中找到它们的比较,所以将这个问题分解为两个更简单、具体的子查询是合理的:
_— “Langchain 在 Github 上有多少星?”
— “Llamaindex 在 Github 上有多少星?”
这些子查询会同时进行,检索到的信息随后被汇总到一个语句中,供大语言模型综合出对原始查询的最终答案。
Query Routing 查询路由
查询路由是指在接收到用户的查询后,由大语言模型决定接下来的操作步骤
常见的做法包括概述查询内容、对特定数据索引进行搜索,或尝试多个不同的处理方法,并将这些方法的结果合成一个答案。
查询路由器的另一个作用是选择数据存储位置来处理用户查询。这些数据存储位置可能是多样的,比如传统的向量存储、图形数据库或关系型数据库,或者是不同层级的索引系统。
设置查询路由器包括决定它可以做出哪些选择。
Fusion Retrieval 融合搜索
结合传统的基于关键词的搜索和现代的语义或向量搜索
传统搜索使用如 tf-idf 或行业标准的 BM25 等稀疏检索算法,而现代搜索则采用语义或向量方法。这两种方法的结合就能产生出色的检索结果。
如何恰当地融合这两种不同相似度得分的检索结果。这个问题通常通过 互惠排名融合 (Reciprocal Rank Fusion) 算法来解决,该算法能有效地对检索结果进行重新排序,以得到最终的输出结果。
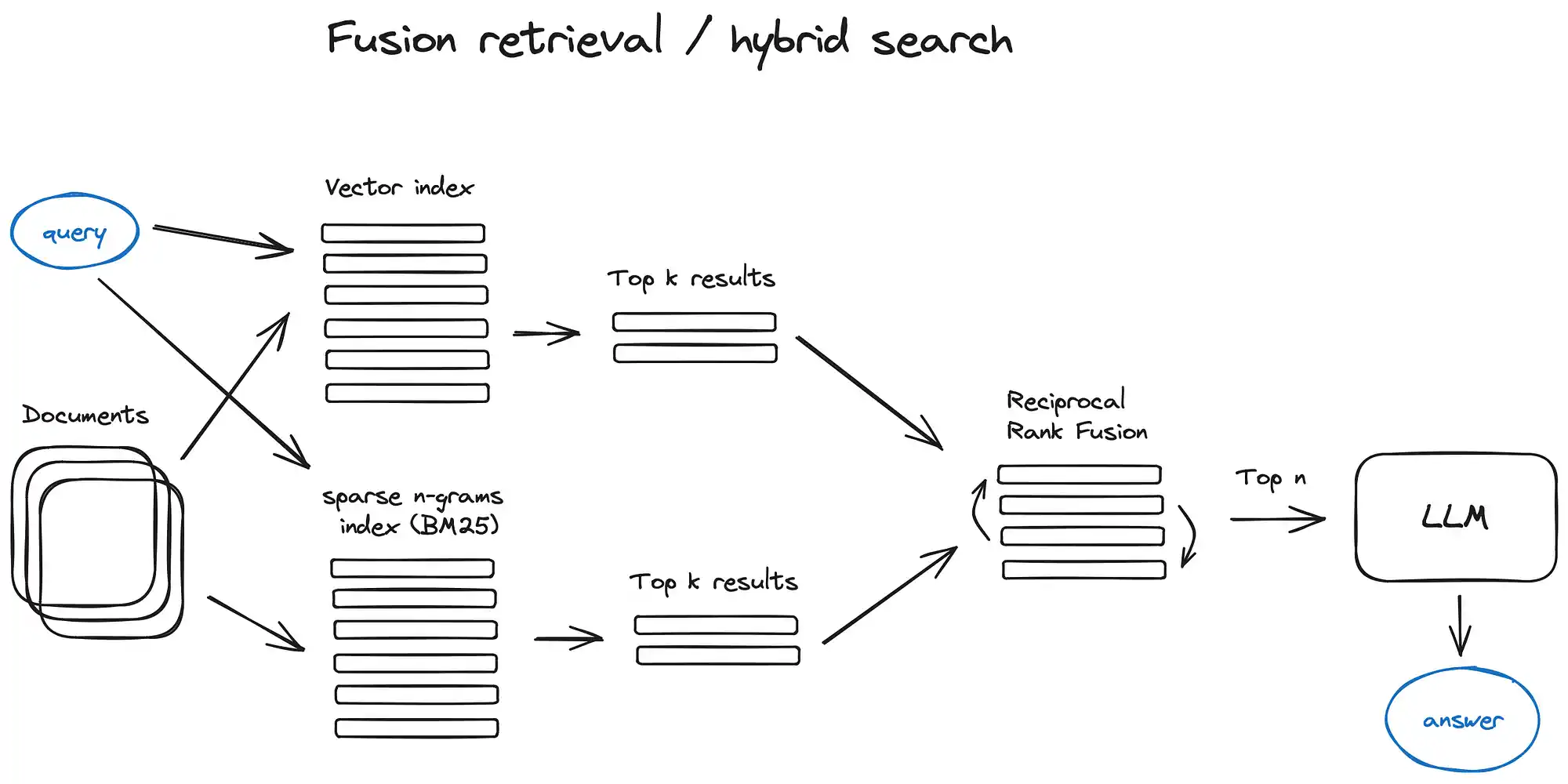
在 LangChain 中,这种方法是通过 合奏检索器 (Ensemble Retriever) 来实现的,该类将您定义的多个检索器结合起来,比如一个基于 faiss 的向量索引和一个基于 BM25 的检索器,并利用 RRF 算法进行结果的重新排序。
Reranking Postprocessing 重排名后处理
在应用了前述的检索算法后,我们得到了初步的搜索结果。下一步是通过过滤、重新排列或转换这些结果来进一步优化它们。
在 LlamaIndex 中,你可以找到多种后处理器,这些处理器能够基于相似度分数、关键词、元数据进行过滤,或者使用其他模型如大语言模型、句子 - 转换器交叉编码器和 Cohere 的重新排名 接口来重新排列结果,甚至可以根据元数据的日期新近度来操作——基本上包括了你能想到的所有功能。
知识来源: