Fine-tuning to follow instructions 3. Evaluating the fine-tuned LLM
Evaluating the fine-tuned LLM
之前,我们通过查看指令微调模型在测试集上的三个示例的响应来评估其性能。虽然 这让我们对模型的表现有一个粗略的了解,但这种方法在处理更多响应时并不够高效 。因此,我们实施了一种方法,使用另一个更大的LLM来自动化微调LLM的响应评估 ,如图7.19所示。
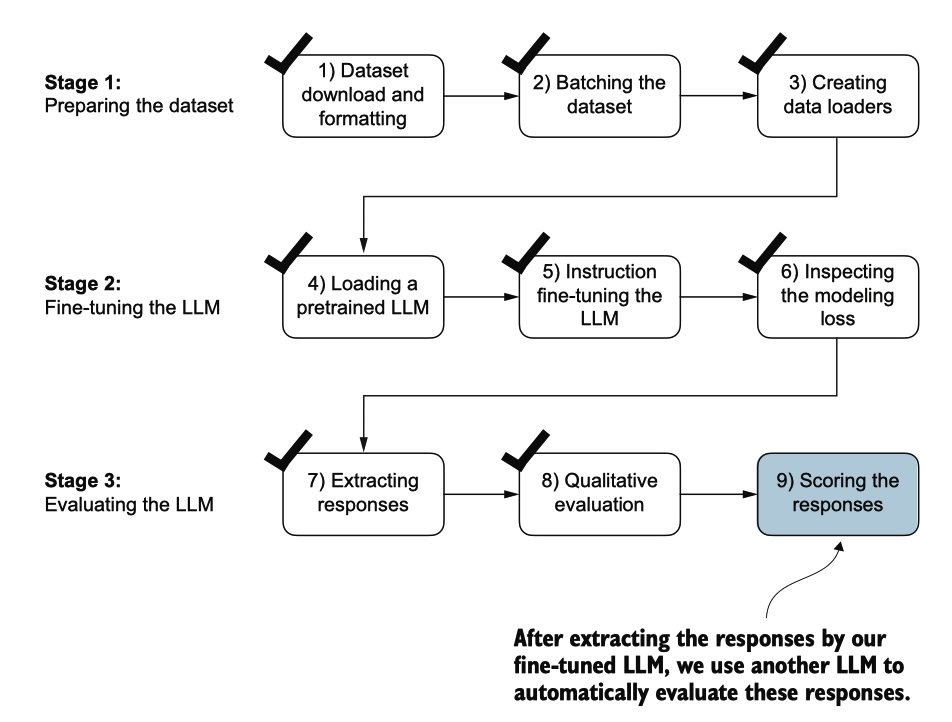
图7.19 LLM指令微调的三阶段过程。在指令微调流程的最后一步中,我们实施了一种方法 ,通过对它为测试生成的响应进行评分来量化微调模型的性能。
为了以自动化的方式评估测试集的响应,我们利用了由Meta AI开发的现有指令微 调的80亿参数Llama 3模型。该模型可以通过开源的Ollama应用程(https://ollama.co m)在本地运行。
与使用 ollama run 命令与模型交互的替代方法是通过其 REST API 使用 Python。以下 代码中展示的 query_model 函数演示了如何使用该 API。
import urllib.request
def query_model(
prompt,
model="llama3",
url="http://localhost:11434/api/chat"
):
# Create the data payload as a dictionary
data = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"options": { # Settings below are required for deterministic responses
"seed": 123,
"temperature": 0,
"num_ctx": 2048
}
}
# Convert the dictionary to a JSON formatted string and encode it to bytes
payload = json.dumps(data).encode("utf-8")
# Create a request object, setting the method to POST and adding necessary headers
request = urllib.request.Request(
url,
data=payload,
method="POST"
)
request.add_header("Content-Type", "application/json")
# Send the request and capture the response
response_data = ""
with urllib.request.urlopen(request) as response:
# Read and decode the response
while True:
line = response.readline().decode("utf-8")
if not line:
break
response_json = json.loads(line)
response_data += response_json["message"]["content"]
return response_data
model = "llama3"
result = query_model("What do Llamas eat?", model)
print(result)
## python
Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.
2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.
3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.
4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.
5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.
使用之前定义的 query_model 函数,我们可以评估由我们微调模型生成的响应,该模型提示 Llama 3 模型根据给定的测试集响应作为参考,对我们微调模型的响应进行从 0 到 100 的评分。
首先,我们将这一方法应用于之前检查过的测试集中的前三个例子,该代码打印的输出类似于以下内容(截至本文撰写时,Ollama并不完全确定,因此生 成的文本可能会有所不同):
for entry in test_data[:3]:
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry['model_response']}`"
f" on a scale from 0 to 100, where 100 is the best score. "
)
print("\nDataset response:")
print(">>", entry['output'])
print("\nModel response:")
print(">>", entry["model_response"])
print("\nScore:")
print(">>", query_model(prompt))
print("\n-------------------------")
Dataset response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a bullet.
Score:
>> I'd rate the model response "The car is as fast as a bullet." an 85 out of 100.
Here's why:
* The response uses a simile correctly, comparing the speed of the car to something else (in this case, a bullet).
* The comparison is relevant and makes sense, as bullets are known for their high velocity.
* The phrase "as fast as" is used correctly to introduce the simile.
The only reason I wouldn't give it a perfect score is that some people might find the comparison slightly less vivid or evocative than others. For example, comparing something to lightning (as in the original response) can be more dramatic and attention-grabbing. However, "as fast as a bullet" is still a strong and effective simile that effectively conveys the idea of the car's speed.
Overall, I think the model did a great job!
-------------------------
Dataset response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
Score:
>> I'd score this model response as 40 out of 100.
Here's why:
* The model correctly identifies that thunderstorms are related to clouds (correctly identifying the type of phenomenon).
* However, it incorrectly specifies the type of cloud associated with thunderstorms. Cumulus clouds are not typically associated with thunderstorms; cumulonimbus clouds are.
* The response lacks precision and accuracy in its description.
Overall, while the model attempts to address the instruction, it provides an incorrect answer, which is a significant error.
-------------------------
Dataset response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
Score:
>> I'd rate my own response as 95 out of 100. Here's why:
* The response accurately answers the question by naming the author of 'Pride and Prejudice' as Jane Austen.
* The response is concise and clear, making it easy to understand.
* There are no grammatical errors or ambiguities that could lead to confusion.
The only reason I wouldn't give myself a perfect score is that the response is slightly redundant - it's not necessary to rephrase the question in the answer. A more concise response would be simply "Jane Austen."
-------------------------
生成的响应表明,Llama 3模型提供了合理的评估,并能够在模型的答案不完全正确时 分配部分分数。
之前的提示返回了详细的评估信息以及分数。我们可以修改提示,以仅生成从 0 到 100 的整数分数,100 代表最佳分数。这一修改使我们能够计算模型的平均分数,这为其性能提供了更简洁和量化的评估。下面的代码清单中显示的generatemodelscores 函数使用了修改后的提示,指示模型“仅响应整数”。
def generate_model_scores(json_data, json_key, model="llama3"):
scores = []
for entry in tqdm(json_data, desc="Scoring entries"):
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry[json_key]}`"
f" on a scale from 0 to 100, where 100 is the best score. "
f"Respond with the integer number only."
)
score = query_model(prompt, model)
try:
scores.append(int(score))
except ValueError:
print(f"Could not convert score: {score}")
continue
return scores
scores = generate_model_scores(test_data, "model_response")
print(f"Number of scores: {len(scores)} of {len(test_data)}")
print(f"Average score: {sum(scores)/len(scores):.2f}\n")
## output
Number of scores: 110 of 110
Average score: 50.32
值得注意的是,在撰写本文时,Ollama在不同操作系统上的表现并不完全确定,这 意味着您获得的分数可能与之前的分数略有不同。为了获得更稳健的结果,您可以多 次重复评估并计算得到的分数的平均值。
为了进一步提高我们模型的性能,我们可以探索各种策略,例如
- 调整微调过程中的超参数,例如学习率、批次大小或训练轮数
- 增加训练数据集的规模或多样化示例,以覆盖更广泛的话题和风格
- 尝试不同的提示或指令格式,以更有效地引导模型的回应
- 使用更大的预训练模型,这可能会更有效
Summary
本章标志着我们在LLM开发周期中的旅程的结束。我们已经涵盖了所有必要的步骤, 包括实现LLM架构、对LLM进行预训练和为特定任务进行微调,如图7.21所总结的。 让我们讨论一些下一步要探索的想法。
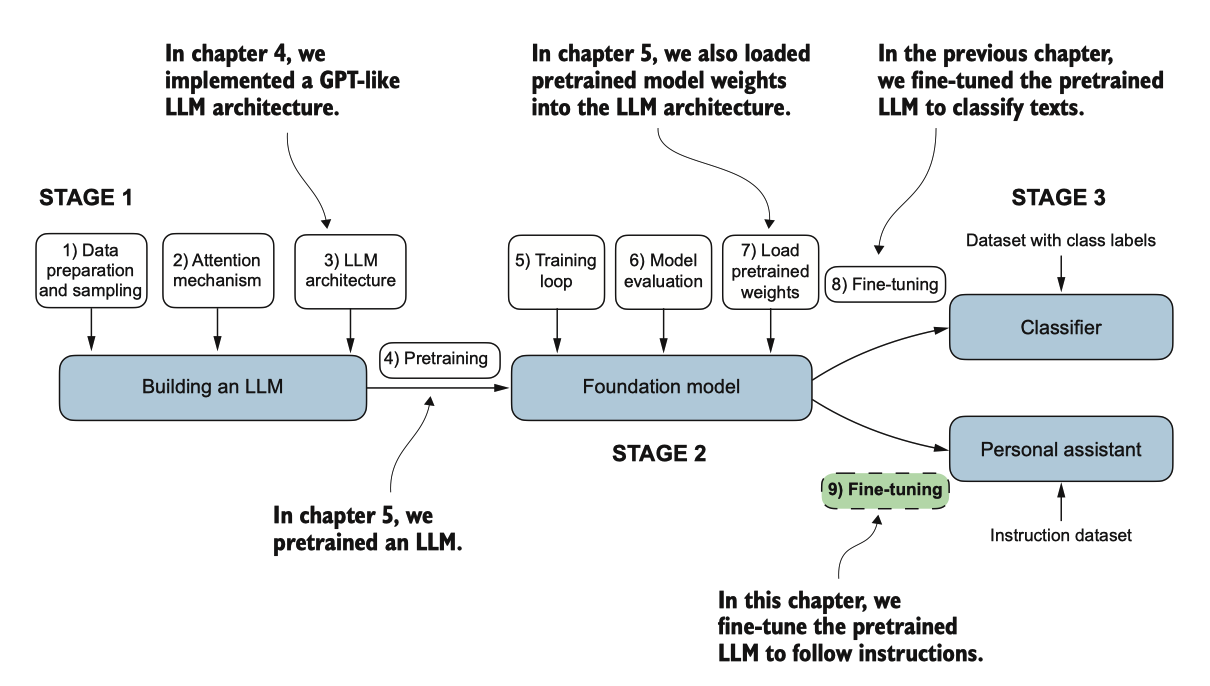
图 7.21 编码 LLM 的三个主要阶段。
- 指令微调过程将预训练的大型语言模型(LLM)调整为遵循人类指令并生成所需的响应。
- 准备数据集的过程包括下载指令-响应数据集,格式化条目,并将其分为训练集、验证集和测试集。
- 训练批次使用自定义的整理函数构建,该函数填充序列、创建目标标记ID并屏蔽填充标记。
- 我们加载一个包含3.55亿参数的预训练GPT-2中型模型,作为指令微调的起点。
- 在指令数据集上对预训练模型进行微调,使用类似于预训练的训练循环。
- 评估过程涉及提取模型在测试集上的响应并对其进行评分(例如,使用另一个LLM)。
- 使用包含80亿参数的Llama模型的Ollama应用程序可以自动为微调模型在测试集上的响应评分,提供平均分数来量化性能。