Pretraining GPT model with unlabeled data 2. Training an LLM
现在终于是实现我们GPTModel进行预训练的代码的时候了。为此,我们专注于一个 简单的训练循环,以保持代码简洁易读。

图 5.11 在 PyTorch 中训练深度神经网络的典型训练循环包含多个步骤,在训练集的各个批次上迭代多个周期。在每个循环中,我们计算每个训练集批次的损失,以确定损失梯度,然后使用这些梯度更新模型权重,从而使训练集损失最小化。
图5.11中的流程图描绘了一个典型的PyTorch神经网络训练工作流,我们用它来训练一 个LLM。它概述了八个步骤,从遍历每个时期开始,处理批量,重置梯度,计算损失和新的梯度,更新权重,并以监控步骤结束,例如打印损失和生成文本样本。
def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
# Initialize lists to track losses and tokens seen
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
# Main training loop
for epoch in range(num_epochs):
model.train() # Set model to training mode
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
tokens_seen += input_batch.numel()
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Print a sample text after each epoch
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
evaluate_model 函数对应于图 5.11中的第 7 步。它在每次模型更新后打印训练集和验证集的损失,因此我们可以评估训练是否改善了模型。
更具体地说,evaluate_model 函数在计算训练集和验证集的损失时,确保模型处于评估模式,并在计算损失时禁用梯度跟踪和 dropout。
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " ")) # Compact print format
model.train()
与evaluatemodel类似,generateandprintsample函数是一种便捷函数,我们用它来跟 踪模型在训练过程中是否有改善。
特别是,generateandprintsample函数接受一个文 本片段(startcontext)作为输入,将其转换为令牌ID,然后将其提供给LLM,以使用 我们之前使用的generatetextsimple函数生成文本样本.
虽然 evaluatemodel 函数给出了模型训练进度的数值估计,但generateandprintsample 文本函数提供了一个由模型生成的具体文本示例,以判断其在训练期间的能力。
[!NOTE] AdamW
Adam优化器是训练深度神经网络的热门选择。然而,在我们的训练循环中,我们选择了AdamW优化器。AdamW是Adam的一种变体,它改进了权重衰减方法,旨在通过惩罚较大的权重来最小化模型复杂度并防止过拟合。这一调整使得AdamW能够实现更有效的正则化和更好的泛化;因此,AdamW在LLM的训练中被广泛使用。
让我们通过使用 AdamW 优化器和我们之前定义的 trainmodelsimple 函数,将 GPTM odel 实例训练 10 个周期,来看一下这一切的实际效果:
# Note:
# Uncomment the following code to calculate the execution time
# import time
# start_time = time.time()
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
# Note:
# Uncomment the following code to show the execution time
# end_time = time.time()
# execution_time_minutes = (end_time - start_time) / 60
# print(f"Training completed in {execution_time_minutes:.2f} minutes.")
Ep 1 (Step 000000): Train loss 9.781, Val loss 9.933
Ep 1 (Step 000005): Train loss 8.111, Val loss 8.339
Every effort moves you,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.661, Val loss 7.048
Ep 2 (Step 000015): Train loss 5.961, Val loss 6.616
Every effort moves you, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and,, and, and,
Ep 3 (Step 000020): Train loss 5.726, Val loss 6.600
Ep 3 (Step 000025): Train loss 5.201, Val loss 6.348
Every effort moves you, and I had been.
Ep 4 (Step 000030): Train loss 4.417, Val loss 6.278
Ep 4 (Step 000035): Train loss 4.069, Val loss 6.226
Every effort moves you know the "I he had the donkey and I had the and I had the donkey and down the room, I had
Ep 5 (Step 000040): Train loss 3.732, Val loss 6.160
Every effort moves you know it was not that the picture--I had the fact by the last I had been--his, and in the "Oh, and he said, and down the room, and in
Ep 6 (Step 000045): Train loss 2.850, Val loss 6.179
Ep 6 (Step 000050): Train loss 2.427, Val loss 6.141
Every effort moves you know," was one of the picture. The--I had a little of a little: "Yes, and in fact, and in the picture was, and I had been at my elbow and as his pictures, and down the room, I had
Ep 7 (Step 000055): Train loss 2.104, Val loss 6.134
Ep 7 (Step 000060): Train loss 1.882, Val loss 6.233
Every effort moves you know," was one of the picture for nothing--I told Mrs. "I was no--as! The women had been, in the moment--as Jack himself, as once one had been the donkey, and were, and in his
Ep 8 (Step 000065): Train loss 1.320, Val loss 6.238
Ep 8 (Step 000070): Train loss 0.985, Val loss 6.242
Every effort moves you know," was one of the axioms he had been the tips of a self-confident moustache, I felt to see a smile behind his close grayish beard--as if he had the donkey. "strongest," as his
Ep 9 (Step 000075): Train loss 0.717, Val loss 6.293
Ep 9 (Step 000080): Train loss 0.541, Val loss 6.393
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back the window-curtains, I had the donkey. "There were days when I
Ep 10 (Step 000085): Train loss 0.391, Val loss 6.452
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed luncheon-table, when, on a later day, I had again run over from Monte Carlo; and Mrs. Gis
正如我们所看到的,训练损失显著改善,从 9.781 的值开始,收敛到 0.391。模型的语 言能力提高了很多。起初,模型只能在起始上下文中添加逗号((Every effort moves you,,,,,,,,,,,,)或重复单词“and”。在训练结束时,它能生成语法正确的文本。
与训练集损失相似,我们可以看到验证损失从高(9.933)开始,并在训练过程中减 少。然而,它从未变得像训练集损失那样小,在第10个时代后保持在6.452。
在更详细地讨论验证损失之前,让我们创建一个简单的图表,显示训练集和验证集损失并排比较:
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
# Plot training and validation loss against epochs
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) # only show integer labels on x-axis
# Create a second x-axis for tokens seen
ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis
ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks
ax2.set_xlabel("Tokens seen")
fig.tight_layout() # Adjust layout to make room
plt.savefig("loss-plot.pdf")
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
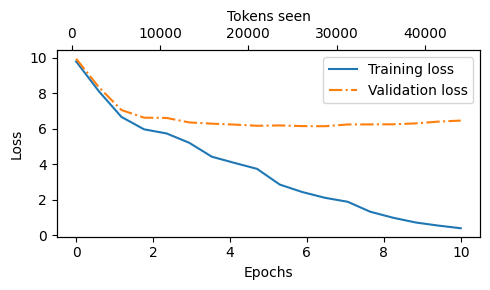
image.png
结果训练和验证损失图如图5.12所示。从中我们可以看到,训练和验证损失在第一个epoch开始改善。然而,损失在第二个epoch后开始发散。这种发散以及验证损失远大于训练损失的事实表明模型正在过拟合训练数据。
我们可以通过搜索生成的文本片段来 确认模型逐字记忆了训练数据,例如在“判决”文本文件中对讽刺的理解显得十分无感。
这种记忆是可以预期的,因为我们正在使用一个非常非常小的训练数据集并且将模型训练多个周期。通常,通常情况下在一个更大的数据集上仅训练一个周期。