Pretraining GPT model with unlabeled data 1.Evaluating generative text models
到目前为止,我们已经实现了数据采样和注意力机制,并编码了LLM架构。现在是 时候实现一个训练函数并进行LLM的预训练。
我们将学习基本的模型评估技术,以 衡量生成文本的质量,这是在训练过程中优化LLM的一个要求。
此外,我们还将讨 论如何加载预训练权重,为我们的LLM提供一个坚实的微调起点。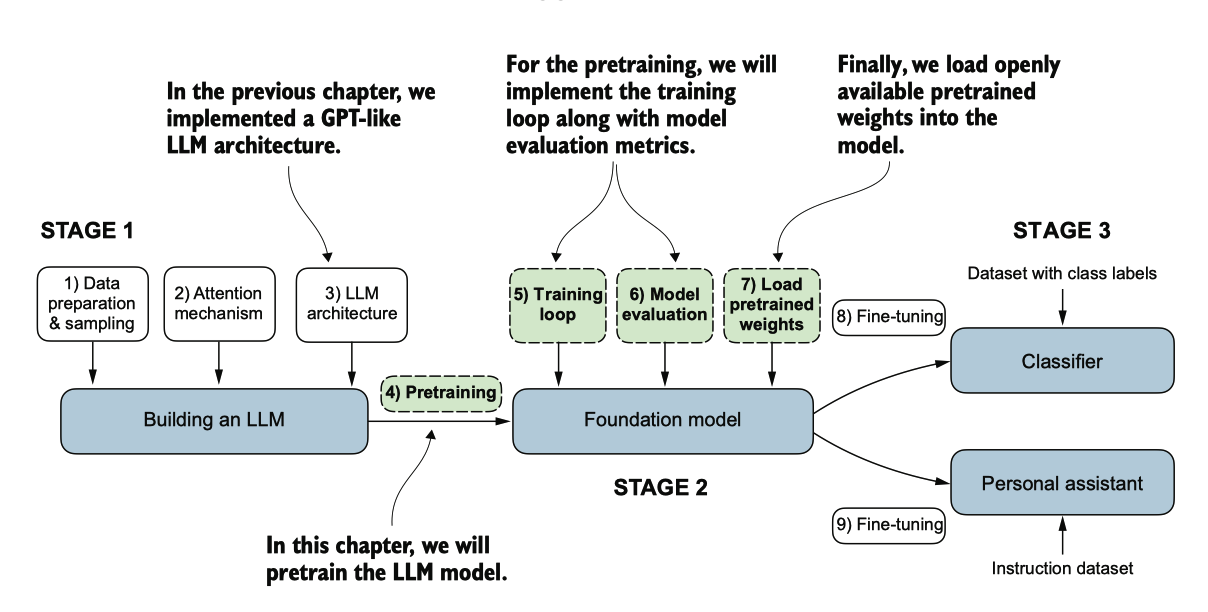
图 5.1 编码 LLM 的三个主要阶段。本章着重于阶段 2:对 LLM 进行预训练(步骤 4),包括实现训练代码(步骤 5 )、评估性能(步骤 6)以及保存和加载模型权重(步骤 7)。
[!NOTE] 权重参数(weight parameters)
在大规模语言模型(LLMs)和其他深度学习模型的背景下,weights 指代学习过程 调整的可训练参数。这些权重也被称为 weight parameters 或简单地称为 parameters 。在像 PyTorch 这样的框架中,这些权重存储在线性层中;我们在第 3 章中使用它 们实现了多头注意力模块,并在第 4 章中实现了 GPTModel。在初始化一个层(new layer = torch.nn.Linear(...))之后,我们可以通过 .weight 属性访问其权重,即 newla yer.weight。此外,为了方便,PyTorch 允许通过方法 model.parameters() 直接访问模型的所有可训练参数,包括权重和偏差,我们将在后面实现模型训练时使用该方法 。
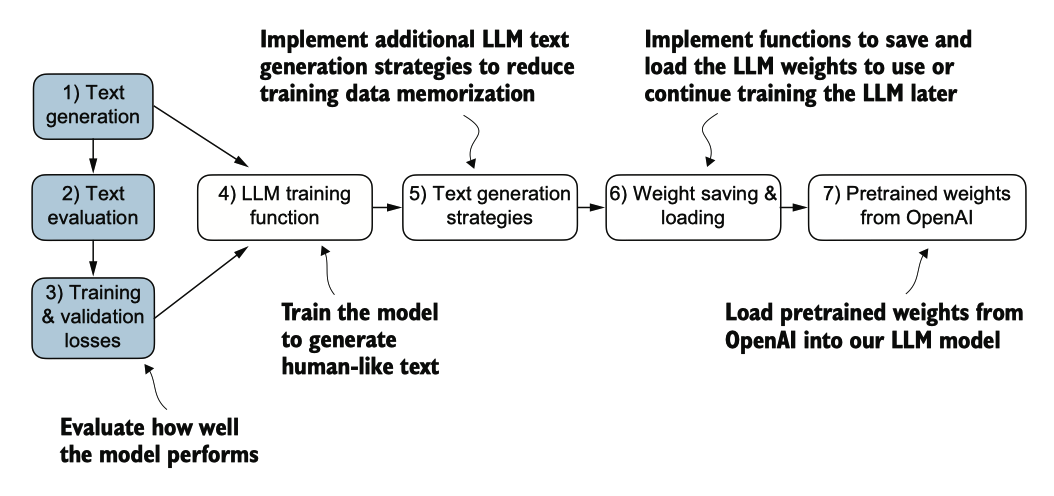
图 5.2 本章所涵盖主题的概述。我们首先回顾文本生成(步骤 1),然后讨论基本模型评估技术(步骤 2)和训练与验证损失(步骤 3)
Using GPT to generate text
让我们设置LLM并简要回顾一下我们在第四章中实现的文本生成过程。我们首先初始 化GPT模型,稍后将使用GPTModel类和GPTCONFIG124M字典对其进行评估和训练
import torch
from previous_chapters import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval(); # Disable dropout during inference
考虑到GPTCONFIG124M字典,与前一章相比,我们唯一的调整是将上下文长度(c ontext_length)减少到256个标记。此修改降低了训练模型的计算需求,使得在标准笔记本电脑上进行训练成为可能。
最初,具有1.24亿参数的GPT-2模型被配置为处理最多1,024个标记。在训练过程之 后,我们将更新上下文大小设置。并加载预训练权重以使用配置为 1,024 个标记上下文长度的模型。
使用 GPTModel 实例,我们采用之前的 generatetextsimple 函数,并引入两个便利的函数:texttotokenids 和 tokenidstotext。这些函数便于文本与标记表示之间的转换,这是一种我们将在本章中使用的技术。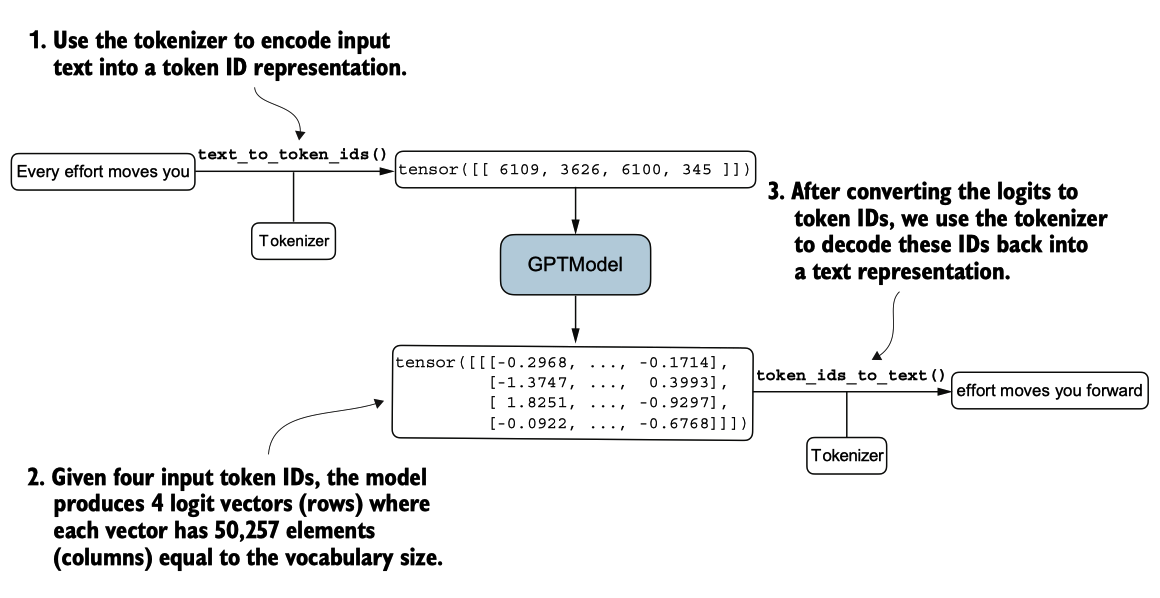
图5.3 生成文本涉及将文本编码成令牌 ID,然后 LLM 将其处理成对数向量。然后将对数向量转换回令牌 ID,反令 牌化为文本表示。
图5.3展示了使用GPT模型的三步文本生成过程。首先,分词器将输入文本转换为一系列标记ID。其次,模型接收这些标记ID并生成相应的logits,这些logits是 表示词汇中每个标记的概率分布的向量。最后,这些logits被转换回标记ID,分词器将其解码为人类可读的文本,完成了从文本输入到文本输出的循环。
我们可以实现文本生成过程,如下所示。
import tiktoken
from previous_chapters import generate_text_simple
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # remove batch dimension
return tokenizer.decode(flat.tolist())
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
## output
Output text:
Every effort moves you rentingetic wasnم refres RexMeCHicular stren
显然,该模型尚未生成连贯的文本,因为它还没有经过训练。要定义什么是“连贯” 或“高质量”的文本,我们必须实施一种数值方法来评估生成的内容。这种方法将使我们能够在整个训练过程中监控和提高模型的性能。
接下来,我们将为生成的输出计算一个 loss metric。这个损失作为训练进展的进度和成功指标。此外,在后面的章节中,当我们微调我们的 LLM 时,我们将回顾评估 模型质量的其他方法。
Calculating the text generation loss
让我们探讨一些技术,用于通过计算 text generation loss 来数值评估训练期间生成的文本质量。
我们将逐步讲解这个主题,并通过一个实际例子使概念清晰且可应用,首先简要回顾一下数据是如何加载的,以及如何通过 generatetextsimple 函数生成文本。

图 5.4 对于左侧显示的三个输入符号,我们计算一个包含对应于词汇中每个符号的概率分数的向量。每个向量中最 高概率分数的索引位置表示最可能的下一个符号 ID。与最高概率分数关联的这些符号 ID 被选择并映射回一个表示 模型生成文本的文本。
图5.4展示了从输入文本到LLM生成文本的整体流程,采用五个步骤的程序。这个 文本生成过程展示了generatetextsimple函数内部的工作原理。在本节稍后,我们需 要执行这些相同的初始步骤,然后才能计算一个损失,以测量生成文本的质量。
图 5.4 概述了使用一个小的七个标记词汇的文本生成过程,以便将此图像适配在单 页上。然而,我们的 GPTModel 使用的是一个更大的词汇表包含 50,257 个单词的词汇量;因此,以下代码中的令牌 ID 将从 0 到 50,256 范围内, 而不是从 0 到 6。
此外,图5.4仅显示一个文本示例(“每一次努力都有所进展”)以简化说明。
GPT generate compare example
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[1107, 588, 11311]]) # " really like chocolate"]
注意,目标是输入,但向前移动了一位,这是我们在第2章数据加载器实现过程中涉 及的一个概念。这个移动策略对于训练模型预测序列中的下一个标记至关重要。
现在我们将输入数据输入模型,以计算两个输入示例的logits向量,每个示例由三个 标记组成。然后,我们应用softmax函数将这些logits转换为概率分数(probas;图5.4, 步骤2):
with torch.no_grad():
logits = model(inputs)
probas = torch.softmax(logits, dim=-1) # Probability of each token in vocabulary
print(probas.shape) # Shape: (batch_size, num_tokens, vocab_size)
## output
torch.Size([2, 3, 50257])
第一个数字 2 对应于输入中的两个示例(行),也称为批量大小。
第二个数字 3 对应 于每个输入(行)中的标记数量。
最后一个数字对应于嵌入维度,由词汇表大小决定 。
通过 softmax 函数将 logits 转换为概率后,generatetextsimple 函数将结果概率分数 转换回文本(图 5.4,步骤 3-5)。我们可以通过对概率分数应用argmax函数来完成步骤3和4,从而获得相应的令牌ID
token_ids = torch.argmax(probas, dim=-1, keepdim=True)
print("Token IDs:\n", token_ids)
## output
Token IDs:
tensor([[[16657],
[ 339],
[42826]], # First batch
[[49906],
[29669],
[41751]]]) # Second batch
最后,第5步将令牌ID转换回文本:
print(f"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}")
print(f"Outputs batch 1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}")
## output
Targets batch 1: effort moves you
Outputs batch 1: Armed heNetflix
当我们解码这些标记时,我们发现这些输出标记与我们希望模型生成的目标标记有很大不同.
模型生成的随机文本与目标文本不同,因为它尚未经过训练。我们现在想通过损失( 图5.5)以数值方式评估模型生成的文本性能。
这不仅有助于衡量生成文本的质量,而且还是实现训练函数的基础,我们将使用该函数来更新模型的权重,以改善生成的文本。
Text Evaluation
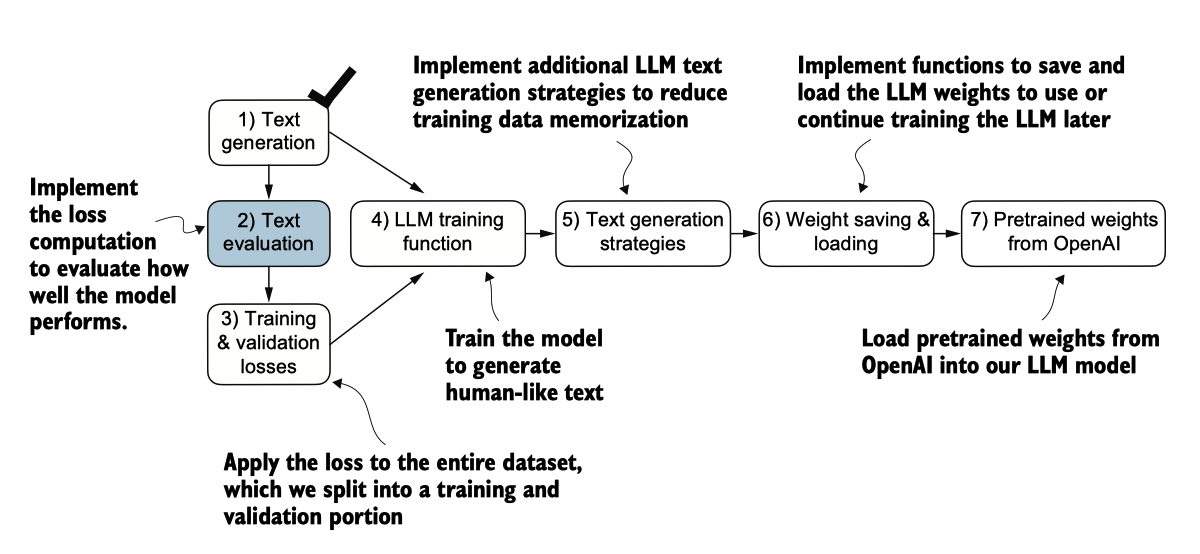
图 5.5 本章涵盖主题的概述。我们已完成步骤 1。现在我们准备实现文本评估函数(步骤 2)。
我们实施的文本评估过程的一部分,如图5.5所示,是衡量生成的标记与正确预测(目 标)之间的“距离”。我们稍后实施的训练函数将利用这些信息调整模型权重,以生 成更类似于(或理想情况下,与之匹配)目标文本的文本。
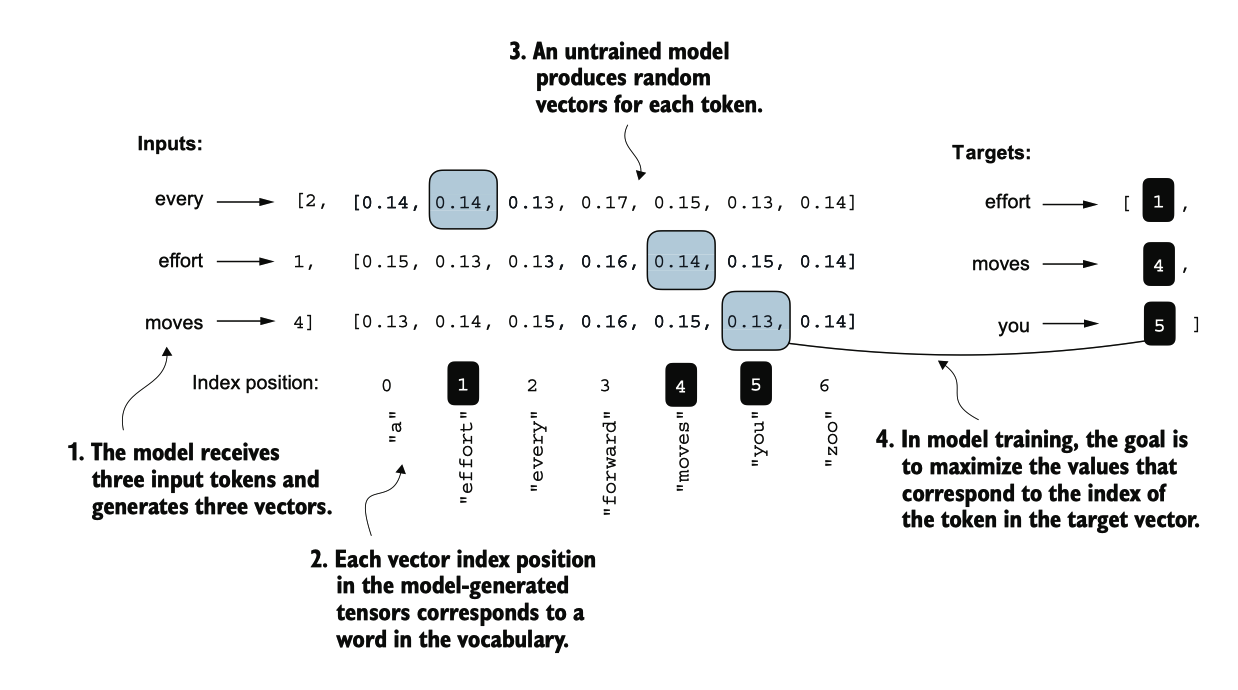
图 5.6 在训练之前,模型产生随机的下一个标记概率向量。模型训练的目标是确保与高亮的目标标记 ID 对应的概 率值被最大化。
该模型训练的目的是提高与正确目标令牌 ID 相对应的索引位置上的 softmax 概率 ,如图 5.6 所示。这个 softmax 概率也将在我们接下来实现的评估指标中使用,以数 值方式评估模型生成的输出:在正确位置上的概率越高,效果越好。
图5.6显示了一个紧凑的七个标记词汇的softmax概率,以便将所有内容放 入一个图中。这意味着起始的随机值会徘徊在1/7附近,大约等于0.14。然而,我们用 于GPT-2模型的词汇有50,257个标记,因此大多数初始概率将徘徊在0.00002(1/50,257 )附近。
对于每个输入文本,我们可以使用以下代码打印对应于目标token的初始softmax概率 得分:
text_idx = 0
target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 1:", target_probas_1)
text_idx = 1
target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 2:", target_probas_2)
## output
Text 1: tensor([7.4541e-05, 3.1061e-05, 1.1563e-05])
Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])
训练 LLM 的目标是最大化正确标记的可能性,这涉及到提高其相对于其他标记的概率。通过这种方式,我们确保 LLM 一贯选择目标标记——本质上是句子中的下一个词——作为它生成的下一个标记。
Loss Explain
[!NOTE] 反向传播
我们如何最大化与目标标记对应的软最大概率值?总体思路是我们更新模型的权重 ,以便模型为我们想要生成的相应标记ID输出更高的值。权重更新是通过一个叫做 backpropagation 的过程完成的,这是一种训练深度神经网络的标准技。
反向传播需要一个损失函数,该函数计算模型预测输出(在这里是与目标令牌 ID 对 应的概率)与实际期望输出之间的差异。这个损失函数衡量模型的预测与目标值之 间的偏差。

图 5.7 计算损失涉及几个步骤。步骤 1 到 3,已经完成,计算与目标张量对应的标记概率。这 些概率随后通过对数转换,并在步骤 4 到 6 中求平均。
接下来,我们将计算两个示例批次的概率得分的损失,targetprobas1 和 targetprobas\2。
主要步骤如图 5.7 所示。由于我们已经应用了步骤 1 到 3 来获得 targetprobas1 和 targetprobas2,因此我们继续进行步骤 4,将 logarithm 应用到概率得分上:
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
print(log_probas)
## output
tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])
在数学优化中,处理概率分数的对数要比直接处理分数更易于管理。
接下来,我们通过计算平均值将这些对数概率合并成一个单一的得分,得到的平均对数概率分数是:
avg_log_probas = torch.mean(log_probas)
print(avg_log_probas)
## output
tensor(-10.7940)
目标是通过在训练过程中更新模型的权重,使平均对数概率尽可能接近 0。
然而,在 深度学习中,常见的做法并不是将平均对数概率推高到 0,而是将负的平均对数概率 降低到 0。负的平均对数概率只是将平均对数概率乘以 -1,这对应于图 5.7 中的第 6 步:
neg_avg_log_probas = avg_log_probas * -1
print(neg_avg_log_probas)
## output
tensor(10.7940)
在深度学习中,将这个负值–10.7940转变为10.7940的术语 称为cross entropy loss(交叉熵损失)。
PyTorch在这里非常方便,因为它已经内置了一个cross_entropy 函数,可以为我们处理图5.7中的所有这六个步骤。
[!NOTE] 交叉熵损失
交叉熵损失在其核心是机器学习和深度学习中一种常用的度量,它衡量两个概率分布之间的差异——通常是标签的真实分布(在这里是数据集中的标记)和来自模型的预测分布(例如,由LLM生成的标记概率)。在机器学习的背景下,特别是在像 PyTorch 这样的框架中,cross_entropy 函数计算离散结果的这个度量,它类似于给定模型生成的令牌概率下目标令牌的负平均对数概率,因此术语“交叉熵”和“负平均对数概率”相关,并且在实践中通常可以互换使用。
在我们应用交叉熵函数之前,先简单回顾一下 logits 和目标张量的形状:
# Logits have shape (batch_size, num_tokens, vocab_size)
print("Logits shape:", logits.shape)
# Targets have shape (batch_size, num_tokens)
print("Targets shape:", targets.shape)
## output
Logits shape: torch.Size([2, 3, 50257])
Targets shape: torch.Size([2, 3])
如我们所见,logits 张量有三个维度:批量大小、标记数量和词汇大小。targets 张量有 两个维度:批量大小和标记数量。
对于 PyTorch 中的交叉熵损失函数,我们希望通过在批次维度上合并这些张量来展平它们:
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
print("Flattened logits:", logits_flat.shape)
print("Flattened targets:", targets_flat.shape)
## output
Flattened logits: torch.Size([6, 50257])
Flattened targets: torch.Size([6])
请记住,目标是我们希望 LLM 生成的令牌 ID,而 logits 是在进入 softmax 函数以获得 概率分数之前的未缩放模型输出。
之前,我们应用了softmax函数,选择了与目标ID对应的概率分数,并计算了负的平 均对数概率。PyTorch的cross_entropy函数将为我们处理所有这些步骤:
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
print(loss)
## output
tensor(10.7940)
所得到的损失与我们之前在手动应用图5.7中的各个步骤时获得的损失相同
[!NOTE] 困惑度(Perplexity)
Perplexity是一个常用的度量,通常与交叉熵损失一起使用,以评估模型在语言建模 等任务中的表现。它可以提供一种更易解释的方式来理解模型在预测序列中下一个 标记时的不确定性。
困惑度衡量模型预测的概率分布与数据集中单词的实际分布之间的匹配程度。与损失类似,较低的困惑度表明模型预测与实际分布更接近。
困惑度可以通过困惑度 = torch.exp(loss) 计算,当应用于先前计算的损失时,它返回tensor(48725.8203)。
困惑度通常被认为比原始损失值更具可解释性,因为它表示模型在每一步对有效词汇量的不确定性。在给定的例子中,这意味着模型对从词汇中生成的48,725个标记中的下一个标记感到不确定。
我们现在已经计算了两个小文本输入的损失以供说明。接下来,我们将把损失计算应用于整个训练和验证集.
Calculating the training and validation set losses
我们必须首先准备训练和验证数据集,以便用于训练 LLM。
图 5.8 完成第 1 步和第 2 步后,包括计算交叉熵损失,我们现在可以将这种损失计算应用于我们将用于模型训练的 整个文本数据集。
为了计算训练和验证数据集上的损失,我们使用一个非常小的文本数据集,即the “The Verdict” short story by Edith Wharton.
[!NOTE] 预训练大型语言模型的成本
为了让我们的项目规模更具可比性,请考虑训练这个拥有70亿参数的Llama 2模型, 这是一个相对流行的开放可用的大型语言模型。该模型在昂贵的A100 GPU上花费了 184,320 GPU小时,处理了2万亿个标记。撰写时,在AWS上运行一个8 × A100云服 务器的费用大约为每小时30美元。粗略估计,这样一个大型语言模型的总训练成本 约为690,000美元(计算方法是将184,320小时除以8,再乘以30美元)。
import os
import urllib.request
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode('utf-8')
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("Characters:", total_characters)
print("Tokens:", total_tokens)
## output
Characters: 20479
Tokens: 5145
接下来,我们将数据集分为训练集和验证集,并使用第二章中的数据加载器为大语 言模型训练准备批次。
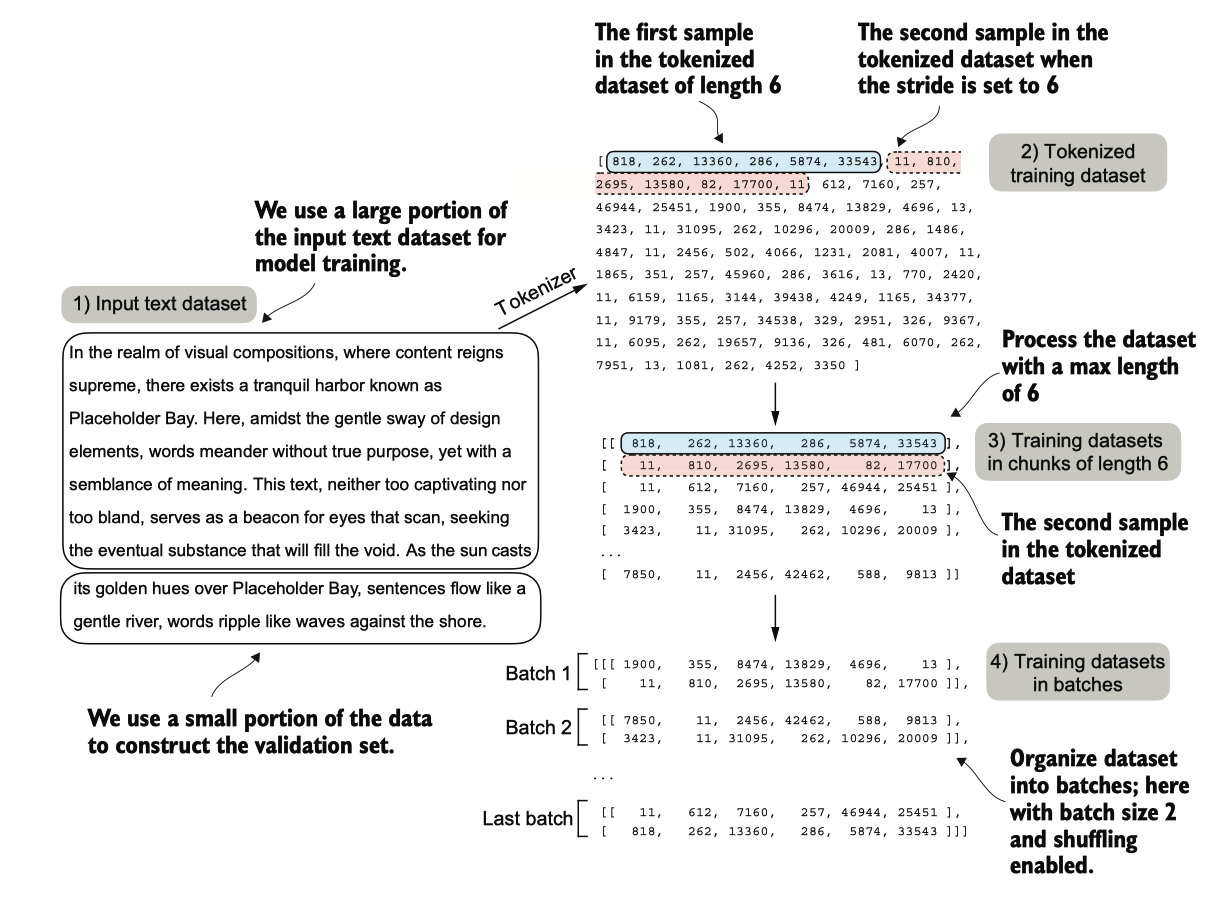
图 5.9 在准备数据加载器时,我们将输入文本分成训练集和验证集部分。然后,我们对文本进行分词(为简单起见 ,仅显示训练集部分的分词)并将分词后的文本划分为用户指定长度的块(这里为 6)。最后,我们打乱行的顺序 ,并将分块的文本组织成批次(这里,批大小为 2),以便我们可以用于模型训练。
这个过程在图5.9中可视化。由于空间限制,我们使用maxlength=6。然而,对于实际的数据加载器,我们将maxlength设置为大语言模型支持的256个标记上下文长度,以便大语言模型在训练期间能够看到更长的文本。
我们正在用相似大小的块呈现的训练数据来训练模型,以简化和提高效率。然而,在 实际操作中,用可变长度的输入训练LLM也可能是有益的,这有助于LLM在使用时更好地对不同类型的输入进行泛化。
Prepare train data
为了实现数据的拆分和加载,我们首先定义一个 train_ratio,将 90% 的数据用于训练 ,剩下的 10% 作为训练期间模型评估的验证数据:
from previous_chapters import create_dataloader_v1
# Train/validation ratio
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
torch.manual_seed(123)
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)
我们使用了相对较小的批量大小以降低计算资源的需求,因为我们处理的是一个非常 小的数据集。实际上,训练大型语言模型(LLMs)时使用 1024 或更大的批量大小并不罕见。
作为一个可选的检查,我们可以遍历数据加载器以确保它们被正确创建:
train_tokens = 0
for input_batch, target_batch in train_loader:
train_tokens += input_batch.numel()
val_tokens = 0
for input_batch, target_batch in val_loader:
val_tokens += input_batch.numel()
print("Training tokens:", train_tokens)
print("Validation tokens:", val_tokens)
print("All tokens:", train_tokens + val_tokens)
## output
Training tokens: 4608
Validation tokens: 512
All tokens: 5120
print("Train loader:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\nValidation loader:")
for x, y in val_loader:
print(x.shape, y.shape)
## python
Train loader:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
Validation loader:
torch.Size([2, 256]) torch.Size([2, 256])
根据前面的代码输出,我们有九个训练集批次,每个批次有两个样本和256个标记。 由于我们只将10%的数据分配用于验证,因此只有一个验证批次,由两个输入示例组 成。如预期的那样,输入数据(x)和目标数据(y)的形状相同(批次大小乘以每个 批次中的标记数),因为目标是输入向右移动一个位置.
How to calculate loss
接下来,我们实现一个工具函数,用于计算通过训练和验证加载器返回的给定批次的交叉熵损失:
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
默认情况下,calclossloader 函数会迭代给定数据加载器中的所有批次,累加 totallo ss 变量中的损失,然后计算并在总批次数上取平均损失。或者,我们可以通过 numbatches 指定较小的批次数,以 加速模型训练期间的评估。
现在让我们看看这个 calclossloader 函数的运作,将其应用于训练集和验证集加载 器:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Note:
# Uncommenting the following lines will allow the code to run on Apple Silicon chips, if applicable,
# which is approximately 2x faster than on an Apple CPU (as measured on an M3 MacBook Air).
# However, the resulting loss values may be slightly different.
#if torch.cuda.is_available():
# device = torch.device("cuda")
#elif torch.backends.mps.is_available():
# device = torch.device("mps")
#else:
# device = torch.device("cpu")
#
# print(f"Using {device} device.")
model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes
torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader
with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
## output
Training loss: 10.98758347829183
Validation loss: 10.98110580444336
损失值相对较高,因为模型尚未经过训练。为了比较,如果模型学习生成在训练和验 证集中的下一个标记,损失值将趋近于0。
接下来,我们将专注于对LLM进行预训练。模型训练后,我们将实施替代文本生成策 略并保存和加载预训练模型权重。