Implement a GPT model 5. GPT model & Generating text
GPT model
在我们用代码组装GPT-2模型之前,让我们先看看它的整体结构, 如图4.15所示, 其中包含我们到目前为止所覆盖的所有概念。如我们所见,Transformer Block在GPT模型架构 中多次重复。在124百万参数的GPT-2模型中,它重复了12次,我们通过GPTCONFIG 124M字典中的n_layers条目来指定。在参数为1,542百万的最大GPT-2模型中,这个Transformer Block重复了48次。
最终Transformer Block输出通过一个最终的层归一化步骤,然后到达线性输出层。该层将变换器的输出映射到高维空间(在这种情况下,50,257个维度,对应模型的词汇大小 ),以预测序列中的下一个标记。

图 4.15 GPT 模型架构的概述,显示数据在 GPT 模型中的流动。
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
[!NOTE] Title
这个 GPTModel 类的 init 构造函数使用通过 Python 字典 cfg 传入的配置初始化 令牌和位置信息嵌入层。这些嵌入层负责将输入令牌索引转换为密集向量并添加位置信息。
接下来,init 方法创建一个与 cfg 中指定的层数相等的 TransformerBlock 模块的 顺序堆栈。在 transformer 块之后,应用了一个 LayerNorm 层,对 transformer 块的输 出进行标准化,以稳定学习过程。最后,定义了一个不带偏置的线性输出头,将 trans former 的输出投影到分词器的词汇空间中,以为词汇中的每个令牌生成 logits。
FeedForward方法接受一批输入令牌索引,计算它们的嵌入,应用位置嵌入,通过变换器块传递序列,规范化最终输出,然后计算 logits,表示下一个令牌的未规范化概率。我们 将在下一节中将这些 logits 转换为令牌和文本输出。
现在让我们使用我们传递给cfg参数的GPTCONFIG 124M字典初始化124百万参数的GPT模型,并使用我们之前创建的批量文本输入进行喂入:
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
## output
Input batch:
tensor([[6109, 3626, 6100, 345], # Token IDs of text1
[6109, 1110, 6622, 257]]) # Token IDs of text2
Output shape: torch.Size([2, 4, 50257])
tensor([[[ 0.3613, 0.4222, -0.0711, ..., 0.3483, 0.4661, -0.2838],
[-0.1792, -0.5660, -0.9485, ..., 0.0477, 0.5181, -0.3168],
[ 0.7120, 0.0332, 0.1085, ..., 0.1018, -0.4327, -0.2553],
[-1.0076, 0.3418, -0.1190, ..., 0.7195, 0.4023, 0.0532]],
[[-0.2564, 0.0900, 0.0335, ..., 0.2659, 0.4454, -0.6806],
[ 0.1230, 0.3653, -0.2074, ..., 0.7705, 0.2710, 0.2246],
[ 1.0558, 1.0318, -0.2800, ..., 0.6936, 0.3205, -0.3178],
[-0.1565, 0.3926, 0.3288, ..., 1.2630, -0.1858, 0.0388]]],
grad_fn=<UnsafeViewBackward0>)
在我们继续编码将模型输出转换为文本的函数之前,让我们花更多时间在模型架构 本身上并分析其大小。使用 numel() 方法,即“元素数量”的简称,我们可以收集模 型参数张量中的总参数数量:
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
## output
Total number of parameters: 163,009,536
之前,我们提到初始化一个具 有1.24亿参数的GPT模型,那么为什么实际参数数量是1.63亿呢?
原因是一个叫做 weight tying 的概念,它在最初的 GPT-2 架构中被使用。这意味着原始的 GPT-2 架构在其输出层中重用了来自the token embedding layer的权重。为了更好地理解,让 我们看看我们通过 GPTModel 之前初始化的标记嵌入层和线性输出层的形状:
print("Token embedding layer shape:", model.tok_emb.weight.shape)
print("Output layer shape:", model.out_head.weight.shape)
## output
Token embedding layer shape: torch.Size([50257, 768])
Output layer shape: torch.Size([50257, 768])
从打印输出中可以看到,这两个层的权重张量具有相同的形状.
由于分词器词汇表中有 50,257 行,令牌嵌入和输出层非常大。根据权重绑定,让我们 从总的 GPT-2 模型计数中移除输出层的参数数量:
total_params_gpt2 = total_params - sum(p.numel() for p in model.out_head.parameters())
print(f"Number of trainable parameters considering weight tying: {total_params_gpt2:,}")
## output
Number of trainable parameters considering weight tying: 124,412,160
正如我们所见,该模型现在只有1.24亿个参数,匹配了GPT-2模型的原始大小。
权重绑定(weight tying)减少了模型整体的内存占用和计算复杂性。然而,根据我的经验,使用单 独的令牌嵌入和输出层可以获得更好的训练和模型性能;因此,我们在我们的GPTMo del实现中使用了单独的层。现代大型语言模型同样如此。
最后,让我们计算一下我们 GPTModel 对象中 1.63 亿个参数的内存需求:
# Calculate the total size in bytes (assuming float32, 4 bytes per parameter)
total_size_bytes = total_params * 4
# Convert to megabytes
total_size_mb = total_size_bytes / (1024 * 1024)
print(f"Total size of the model: {total_size_mb:.2f} MB")
## output
Total size of the model: 621.83 MB
现在我们已经实现了GPTModel架构,并且看到它输出形状为[batchsize, numtokens, vocab_size]的数值张量,接下来让我们编写代码将这些输出张量转换为文本。
Generating text
我们现在将实现将GPT模型的张量输出转换回文本的代码。在开始之前,让我们简要 回顾一下像LLM这样的生成模型是如何一次生成一个词(或标记)文本的。
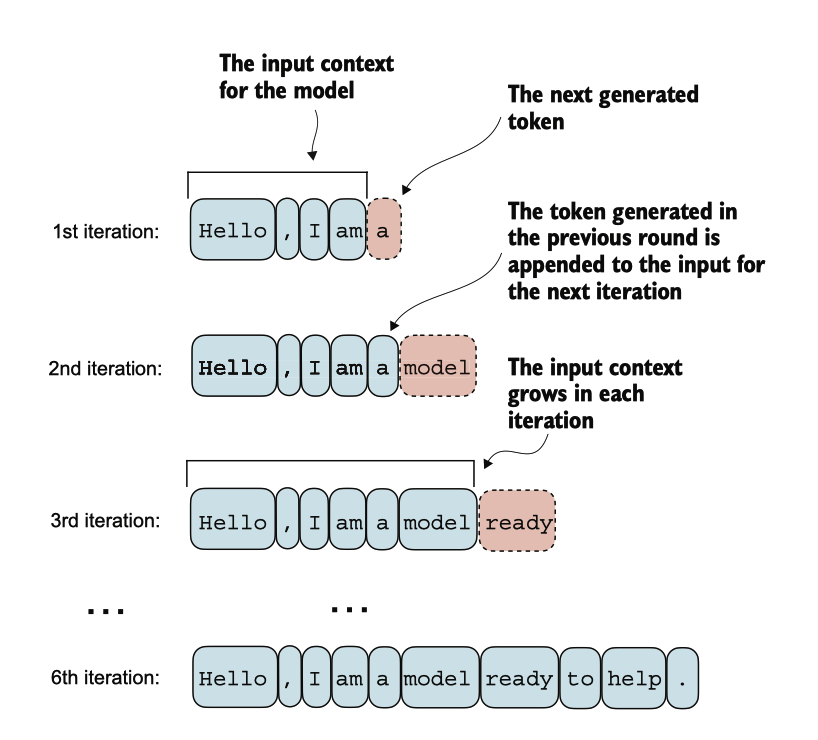
图 4.16 LLM 逐步生成文本的过程,每次生成一个标记。
图 4.16 展示了一步步的过程,通过该过程,GPT 模型根据输入上下文生成文本, 例如“你好,我是。”随着每次迭代,输入上下文不断增加,使模型能够生成连贯且 与上下文相符的文本。在第六次迭代时,模型构造了一个完整的句子:“你好,我是 一个准备帮助的模型。”我们已经看到,我们当前的 GPTModel 实现输出形状为 [batc hsize, numtoken, vocab_size] 的张量。
现在问题是:GPT 模型如何从这些输出张量生 成文本?
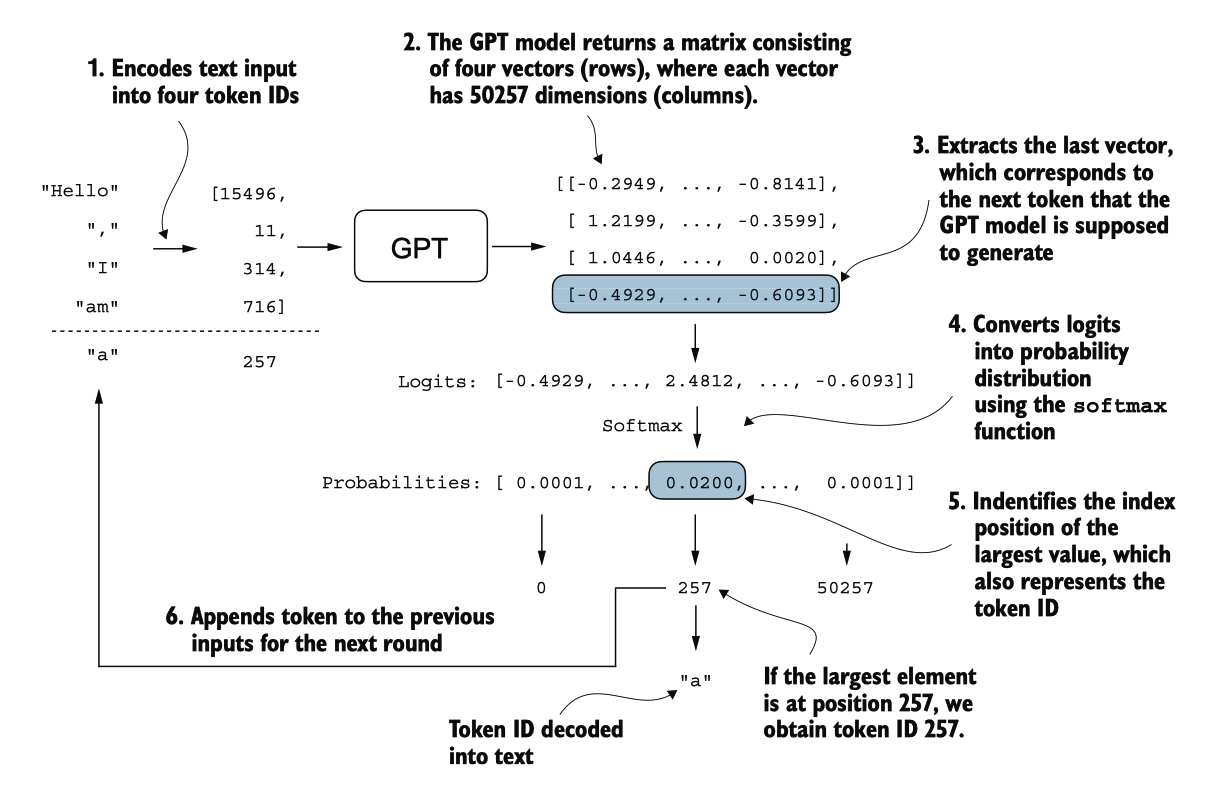
图 4.17 显示了 GPT 模型中文本生成的机制,通过展示令牌生成过程中的单次迭代。
下一词生成过程如图4.17所示,说明了GPT模型在给定输入的情况下生成下一个词 的单个步骤。
在每一步中,模型输出一个矩阵,矩阵中的向量代表潜在的下一个词。 与下一个词对应的向量被提取并通过softmax函数转换为概率分布。在包含结果概率分 数的向量中,找到最高值的索引,这个索引对应于词的ID。然后,将这个词的ID解码 回文本,生成序列中的下一个词。最后,这个词被添加到之前的输入中,形成下一个 子迭代的新输入序列。
这一逐步过程使模型能够顺序生成文本,从最初的输入上下文中构建连贯的短语和句子。
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (batch, n_tokens) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_tokens, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Apply softmax to get probabilities
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# Get the idx of the vocab entry with the highest probability value
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
这段代码演示了使用PyTorch为语言模型实现生成循环的简单实现。它迭代生成指定数 量的新令牌,裁剪当前上下文以适应模型的最大上下文大小,计算预测,然后根据最 高概率预测选择下一个令牌。
为了编码 generatetextsimple 函数,我们使用 softmax 函数将 logits 转换为概率分 布,从中通过 torch.argmax 确定值最高的位置。softmax 函数是单调的,这意味着它在 转换为输出时保持输入的顺序。因此,实际上,softmax 步骤是多余的,因为 softmax 输出张量中得分最高的位置与 logits 张量中的位置是相同的。
换句话说,我们可以直接对 logits 张量应用 torch.argmax 函数,获得相同的结果。然而,我提供转换的代码 以说明将 logits 转换为概率的完整过程,这可以增加额外的直觉,使得模型生成最可 能的下一个标记,这被称为 greedy decoding。
在下一章中,我们实现GPT训练代码时,将使用额外的采样技术来修改softmax输出 ,以便模型不会总是选择最可能的标记。这在生成的文本中引入了可变性和创造性。
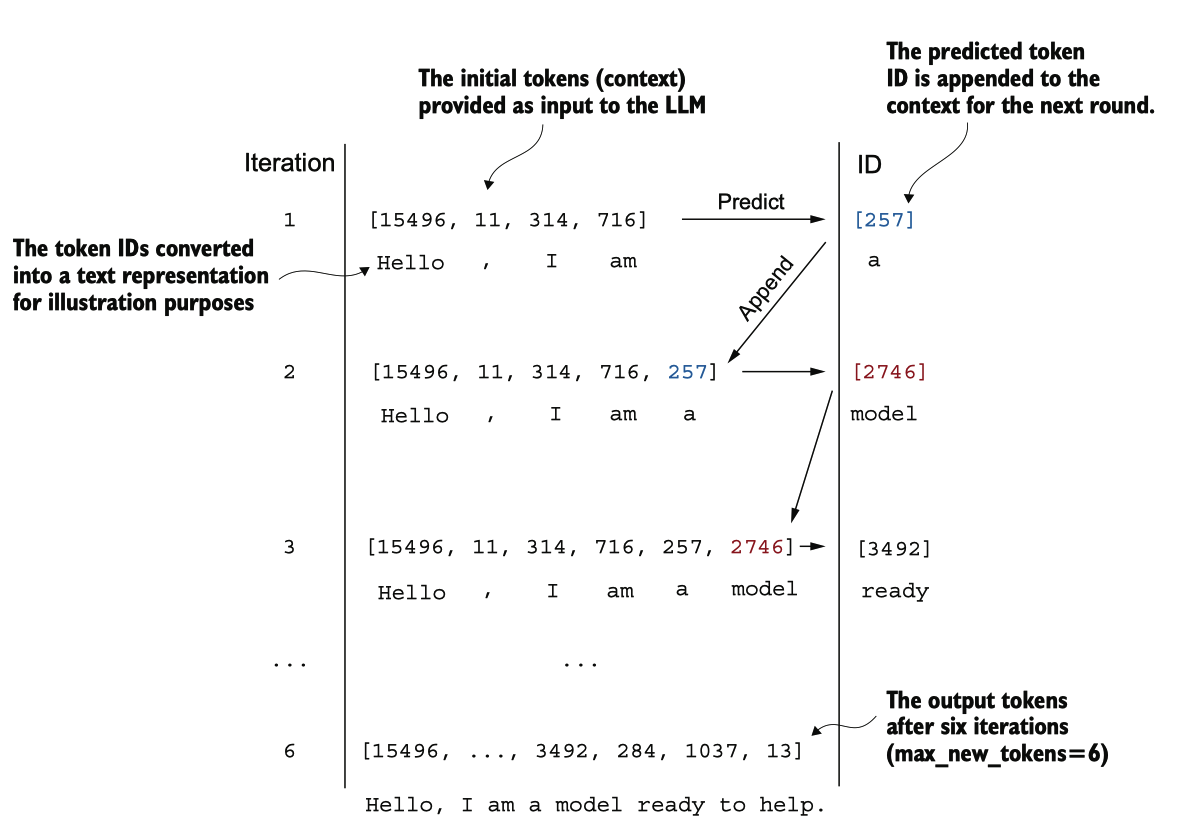
图 4.18 六次标记预测周期的迭代,其中模型将初始标记 ID 的序列作为输入,预测下一个标记,并将该标记附加到 输入序列中以进行下一次迭代。
这个逐个生成令牌 ID 并使用 generatetextsimple 函数将其附加到上下文中的过程 在图 4.18 中进一步说明。(每次迭代的令牌 ID 生成过程在图 4.17 中详细描述。)
我们以迭代的方式生成令牌 ID。例如,在迭代 1 中,模型提供了与“你好,我是”对应 的令牌,预测下一个令牌(ID 为 257,即“一个”),并将其附加到输入中。这个过 程重复进行,直到模型在六次迭代后生成完整句子“你好,我是一个准备帮助的模型 ”。
现在让我们尝试用“你好,我是”作为模型输入的上下文来调用generatetextsimpl e函数。首先,我们将输入上下文编码为令牌ID:
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)
## output
encoded: [15496, 11, 314, 716]
encoded_tensor.shape: torch.Size([1, 4])
接下来,我们将模型置于.eval()模式。这会禁用像dropout这样的随机组件,这些组件 仅在训练期间使用,并在编码输入张量上使用generatetextsimple函数:
model.eval() # disable dropout
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))
## output
Output: tensor([[15496, 11, 314, 716, 27018, 24086, 47843, 30961, 42348, 7267]])
Output length: 10
decoded_text = tokenizer.decode(out.squeeze(0).tolist())
print(decoded_text)
##output
Hello, I am Featureiman Byeswickattribute argue
正如我们所见,模型生成了无意义的文字,发生了什么?模型无法产生连贯文本的原因是我们尚未对其 进行训练。到目前为止,我们只实现了GPT架构,并用初始随机权重初始化了一个GPT模型实例。
Summary
- 层归一化(Layer normalization)通过确保每一层的输出具有一致的均值和方差来稳定训练。
- Shortcut connections是跳过一个或多个层的连接,通过将一个层的输出直接传递给更深的层,这有助于缓解训练深度神经网络时出现的梯度消失问题,尤其是在训练大规模语言模型(LLMs)时。
- Transformer Block是 GPT 模型的核心结构组件,结合了带有掩蔽的多头注意力模块和使用 GELU 激活函数的全连接前馈网络。
- GPT 模型是具有大量参数的 LLM,通过多个重复的 Transformer Block构建,参数量从数百万到数十亿不等。
- GPT 模型有不同的规模,例如,124百万、345百万、762百万和1,542百万参数,我们可以使用相同的 GPTModel Python 类来实现这些模型。
- GPT 类似的 LLM 的文本生成能力涉及将输出张量解码为可读的文本,通过根据给定的输入上下文一次预测一个标记的方式进行。
- 如果没有训练,GPT 模型会生成不连贯的文本,这凸显了训练对于生成连贯文本的重要性。