Implement a GPT model 3. FeedForward network with GELU activations
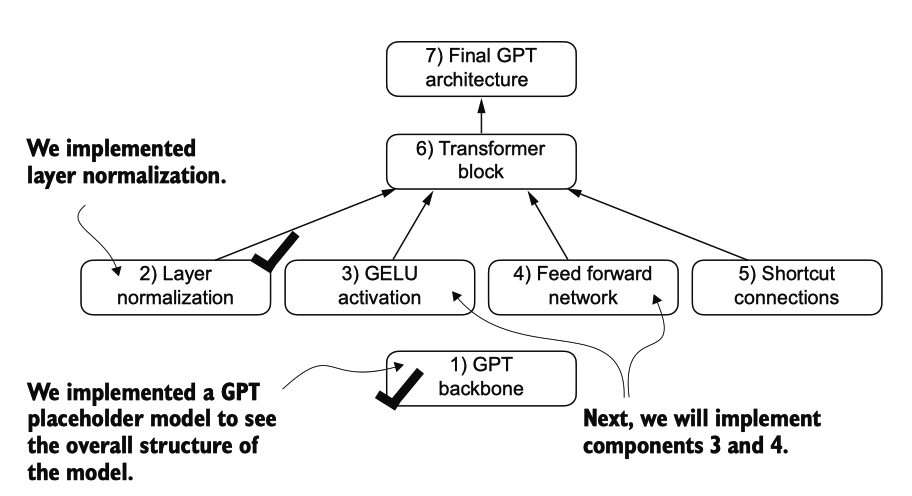
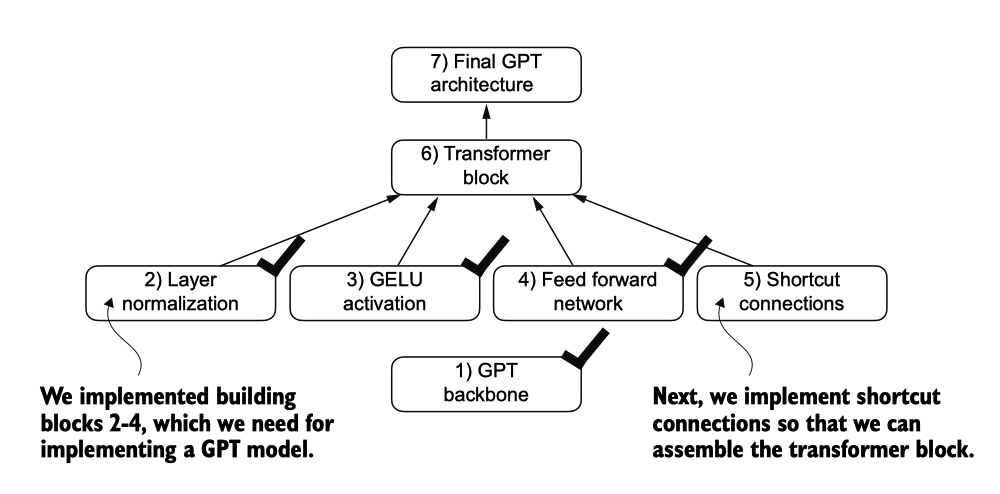
The building blocks necessary to build the GPT architecture. So far, we have completed the GPT backbone and layer normalization. Next, we will focus on GELU activation and the feed forward network.
接下来,我们将实现一个小型神经网络子模块,用作LLMs中的变换器块的一部分。 我们首先实现GELU激活函数,它在这个神经网络子模块中起着关键作用。
历史上,由于其简单性和在各种神经网络架构中的有效性,ReLU 激活函数在深度学习中被广泛使用。然而,在大型语言模型(LLMs)中,除了传统的 ReLU 之外,还采用了几种其他激活函数。两个显著的例子是 GELU (Gaussian error linear unit) 和 SwiGLU (Swish-gated linear unit)。
GELU 和 SwiGLU 是更复杂且平滑的激活函数,分别结合了高斯和 Sigmoid 门控线性单元。与更简单的 ReLU 不同,它们为深度学习模型提供了更好的性能。
GELU activation
GELU 激活函数可以通过多种方式实现;确切的版本定义为 GELU(x) = x⋅Φ(x),其 中 Φ(x) 是标准高斯分布的累积分布函数。然而,在实践中,通常实现一种计算成本 较低的近似(原始 GPT-2 模型也是使用这一近似训练的,该近似是通过曲线拟合得到 的):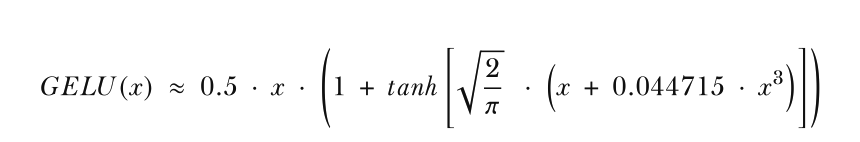
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
接下来,为了了解这个GELU函数的外观以及它与ReLU函数的比较,让我们将这两个 函数并排绘制
import matplotlib.pyplot as plt
gelu, relu = GELU(), nn.ReLU()
# Some sample data
x = torch.linspace(-3, 3, 100)
y_gelu, y_relu = gelu(x), relu(x)
plt.figure(figsize=(8, 3))
for i, (y, label) in enumerate(zip([y_gelu, y_relu], ["GELU", "ReLU"]), 1):
plt.subplot(1, 2, i)
plt.plot(x, y)
plt.title(f"{label} activation function")
plt.xlabel("x")
plt.ylabel(f"{label}(x)")
plt.grid(True)
plt.tight_layout()
plt.show()
如我们在图4.8的结果图中所见,ReLU(右)是一个分段线性函数,当输入为正时, 直接输出输入值;否则,输出零。GELU(左)是一个光滑的非线性函数,它近似于ReLU,但对于几乎所有负值(除了大约 x = –0.75),其梯度均为非零。
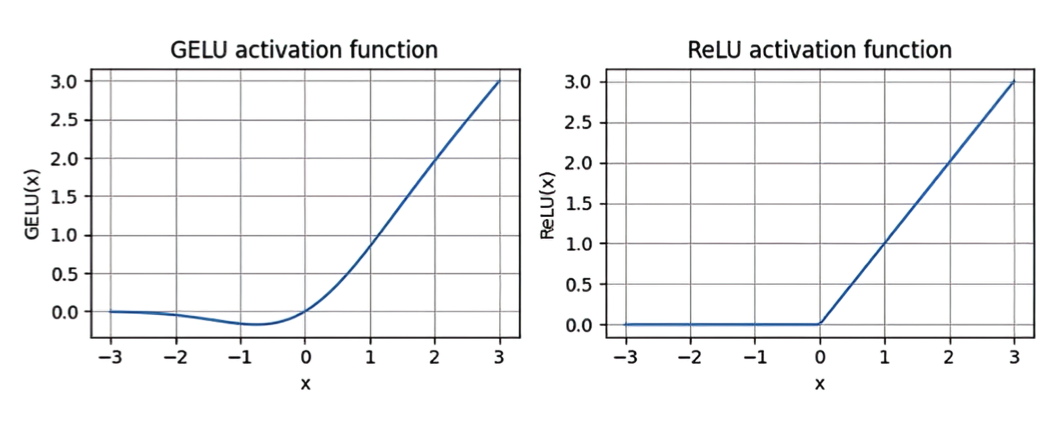
图示4.8 使用 matplotlib 绘制的 GELU 和 ReLU 输出图。x 轴显示函数输入,y 轴显示函数输出。
GELU的光滑性可以在训练过程中带来更好的优化特性,因为它允许对模型参数进行 更微妙的调整。
相比之下,ReLU在零点处有一个尖锐的角(图4.18,右侧),这有时 会使优化变得更加困难,尤其是在非常深或具有复杂架构的网络中。
此外,与ReLU不同,后者对任何负输入输出零,GELU允许负值有一个小的、非零的输出。这一特征 意味着在训练过程中,接收负输入的神经元仍然可以对学习过程做出贡献,尽管程度低于正输入.
FeedForward Module
接下来,让我们使用GELU函数实现小型神经网络模块FeedForward,这将在后面的LLM变换器模块中使用。
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
print(GPT_CONFIG_124M["emb_dim"])
## output
768
如我们所见,FeedForward模块是一个由两个线性层和一个GELU激活函数组成的小型 神经网络。在124百万参数的GPT模型中,它通过GPTCONFIG124M字典接收嵌入大小为768的输入批次,其中GPTCONFIG124M[emb_dim] = 768。
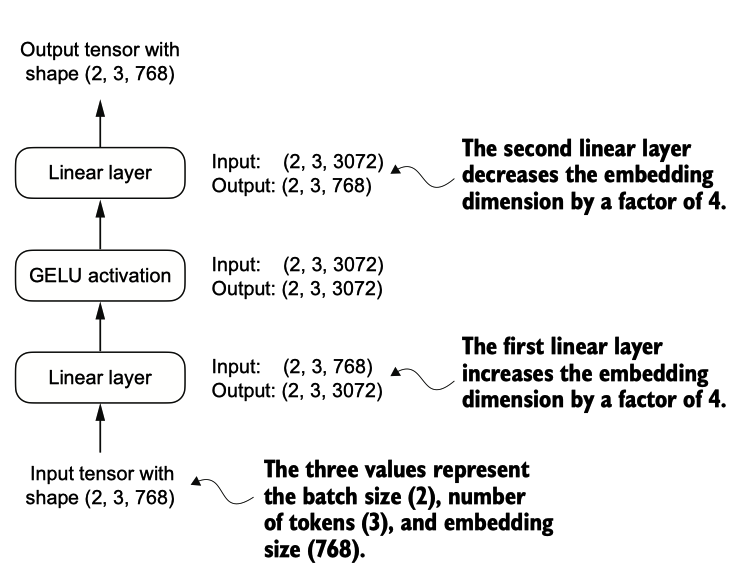
图4.9 前馈神经网络各层之间连接的概述。
该神经网络可以适应可变的批量大小和输入中的令牌数量。然而,每个令牌的嵌入大小在初始化权重时是确定并固定的。
根据图4.9中的示例,让我们初始化一个新的前馈模块,其令牌嵌入大小为768,并给 它输入一个包含两个样本和每个样本三个令牌的批量输入:
ffn = FeedForward(GPT_CONFIG_124M)
# input shape: [batch_size, num_token, emb_size]
x = torch.rand(2, 3, 768)
out = ffn(x)
print(out.shape)
## output
torch.Size([2, 3, 768])
FeedForward 模块在增强模型从数据中学习和泛化的能力方面发挥了关键作用。尽管该模块的输入和输出维度相同,但它在内部通过第一个线性层将嵌入维度扩展到更高的维度空间.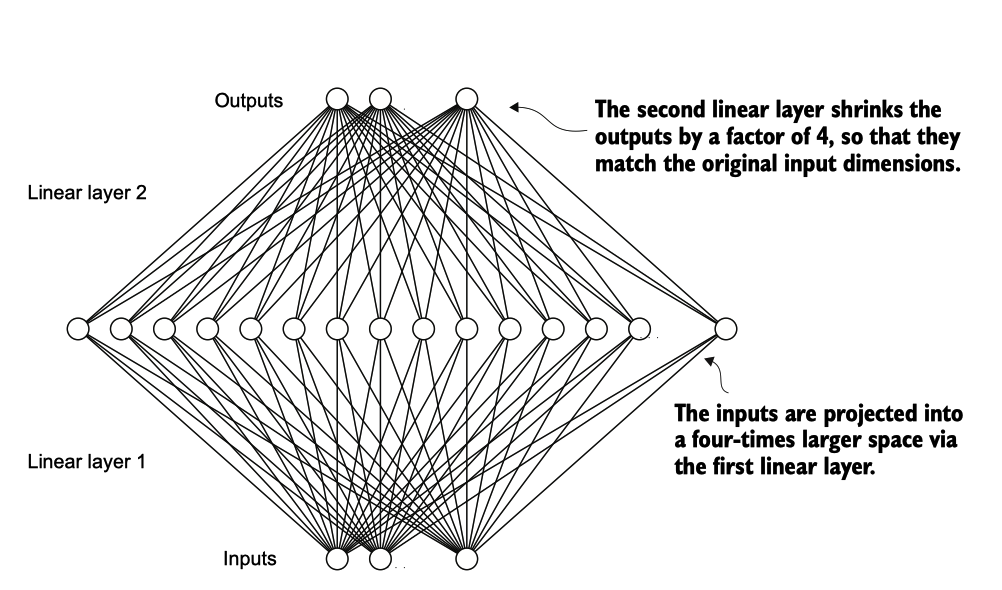
图4.10 前向神经网络中层输出的扩展和收缩示意图。
如图 4.10 所示。首先,输入从768扩展到3,072个值,扩展因子为4。然后,第二层将3,072个值压缩回768维表示。该扩展之后是非线性的 GELU 激活,然后通过第二个线 性变换收缩回原始维度。这种设计允许探索更丰富的表示空间。
此外,输入和输出维度的统一简化了架构,使得可以堆叠多个层,如我们随后将要做 的那样,而无需在它们之间调整维度,从而使模型更加可扩展。
Next Build