Implement a GPT model 1. LLM architecture
我们已经涵盖了 LLM 架构的多个方面,例如输入标记化、嵌入和掩码多头注意力 模块。现在,我们将实现 GPT 模型的核心结构,包括它的 transformer blocks,我们稍 后将训练它以生成类似人类的文本。
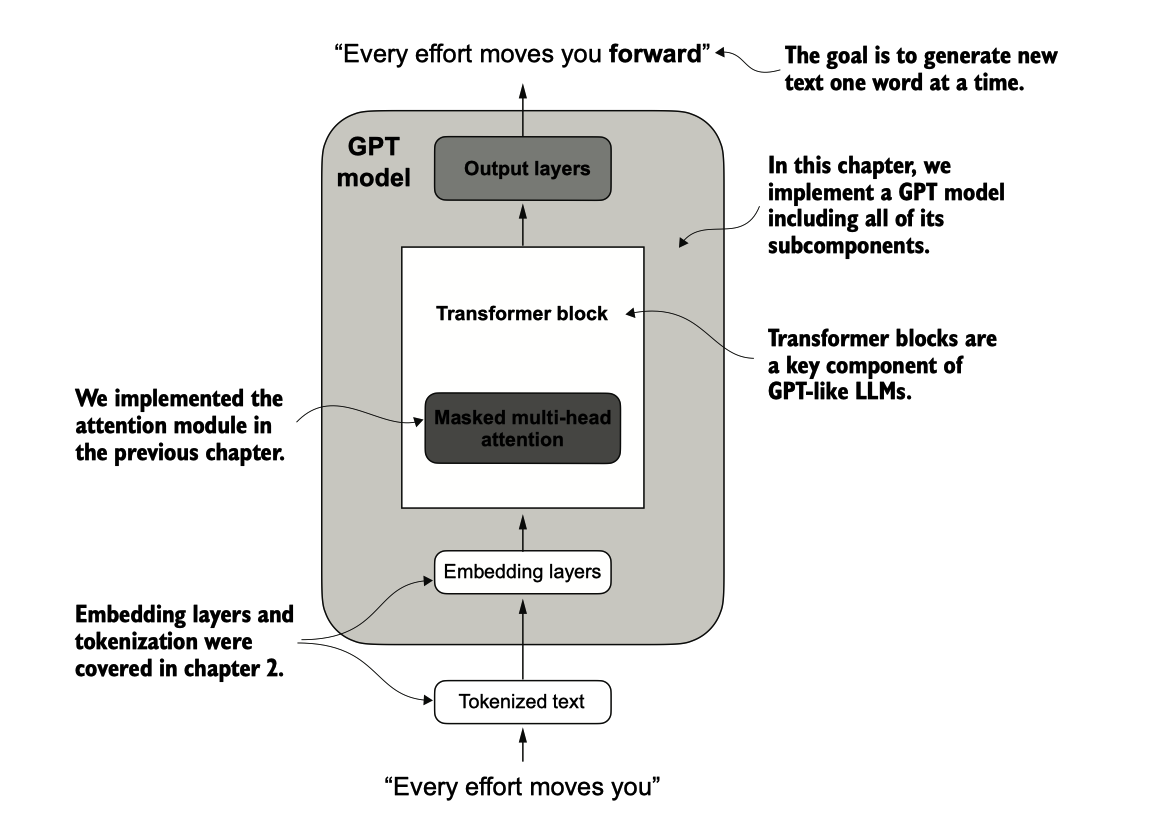
GPT模型。除了嵌入层外,它还由一个或多个变换器块组成,这些变换器块包含我们 之前实现的掩蔽多头注意力模块。
例如,在一个由2,048 × 2,048维权重矩阵(或张量)表示的神经网络层中,该矩阵的 每个元素都是一个参数。由于有2,048行和2,048列,因此该层的参数总数是2,048乘以2 ,048,即4,194,304个参数。
GPT-2 Config
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 1024,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
- vocab_size 指的是一个包含 50,257 个单词的词汇表,由 BPE 分词器使用(见第二章)。
- context_length 表示模型通过位置嵌入可以处理的最大输入标记数量。
- emb_dim 表示嵌入大小,将每个标记转换为一个 768 维的向量。
- n_heads 指的是多头注意力机制中的注意力头数量。
- n_layers 指定模型中的变换器块数量,我们将在即将到来的讨论中涵 盖这一点。
- drop_rate 表示丢弃机制的强度(0.1 表示随机丢弃 10% 的隐藏单元),以防止过拟。
- qkv_bias 决定是否在多头注意力的线性层中包含查询、键和值计算的偏 置向量。我们最初将禁用此项,以遵循现代 LLM 的规范,但在后续我们从 OpenAI 加载预训 练的 GPT-2 权重到模型时,会重新考虑这一点
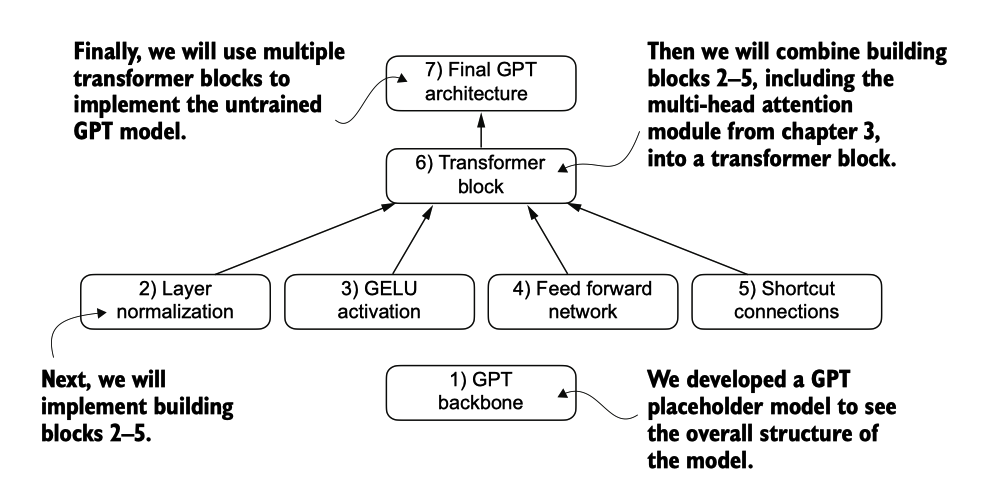
Build Step1. GPTModel
https://picbed.fjhdream.cn/202502101612315.png
import torch
import torch.nn as nn
class DummyGPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
# Use a placeholder for TransformerBlock
self.trf_blocks = nn.Sequential(
*[DummyTransformerBlock(cfg) for _ in range(cfg["n_layers"])])
# Use a placeholder for LayerNorm
self.final_norm = DummyLayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
class DummyTransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
# A simple placeholder
def forward(self, x):
# This block does nothing and just returns its input.
return x
class DummyLayerNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-5):
super().__init__()
# The parameters here are just to mimic the LayerNorm interface.
def forward(self, x):
# This layer does nothing and just returns its input.
return x
DummyGPTModel 类在此代码中定义了一个使用 PyTorch 神经网络模块 (nn.Module) 的简化版类 GPT 模型。DummyGPTModel 类中的模型架构由 token 和位置嵌入、drop out、一系列变换器块 (DummyTransformerBlock)、最终的层归一化 (DummyLayerNorm ) 以及一个线性输出层 (outhead) 组成。配置通过 Python 字典传入,例如我们之前创建的 GPTCONFIG_124M 字典。
forward方法描述了数据在模型中的流动:它为输入索引计算标记和位置嵌入,应用 dr opout,将数据通过 transformer 块处理,应用归一化,最后通过线性输出层生成 logits 。
Build Step2. tiktoken
接下来,我们将准备输入数据,并初始化一个新的GPT模型以演示其使用。基于我们对分词器的编码(见第2章),现在让我们考虑一个高层次的概述,说明数据是如何进出GPT模型的.
为了实现这些步骤,我们使用第2章中的tiktoken分词器对包含两个文本输入的批次 进行分词,以供GPT模型使用:
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
batch = []
txt1 = "Every effort moves you"
txt2 = "Every day holds a"
batch.append(torch.tensor(tokenizer.encode(txt1)))
batch.append(torch.tensor(tokenizer.encode(txt2)))
batch = torch.stack(batch, dim=0)
print(batch)
## output
tensor([[6109, 3626, 6100, 345], #The first row corresponds to the first text,
[6109, 1110, 6622, 257]]) #The second row corresponds to the second text.
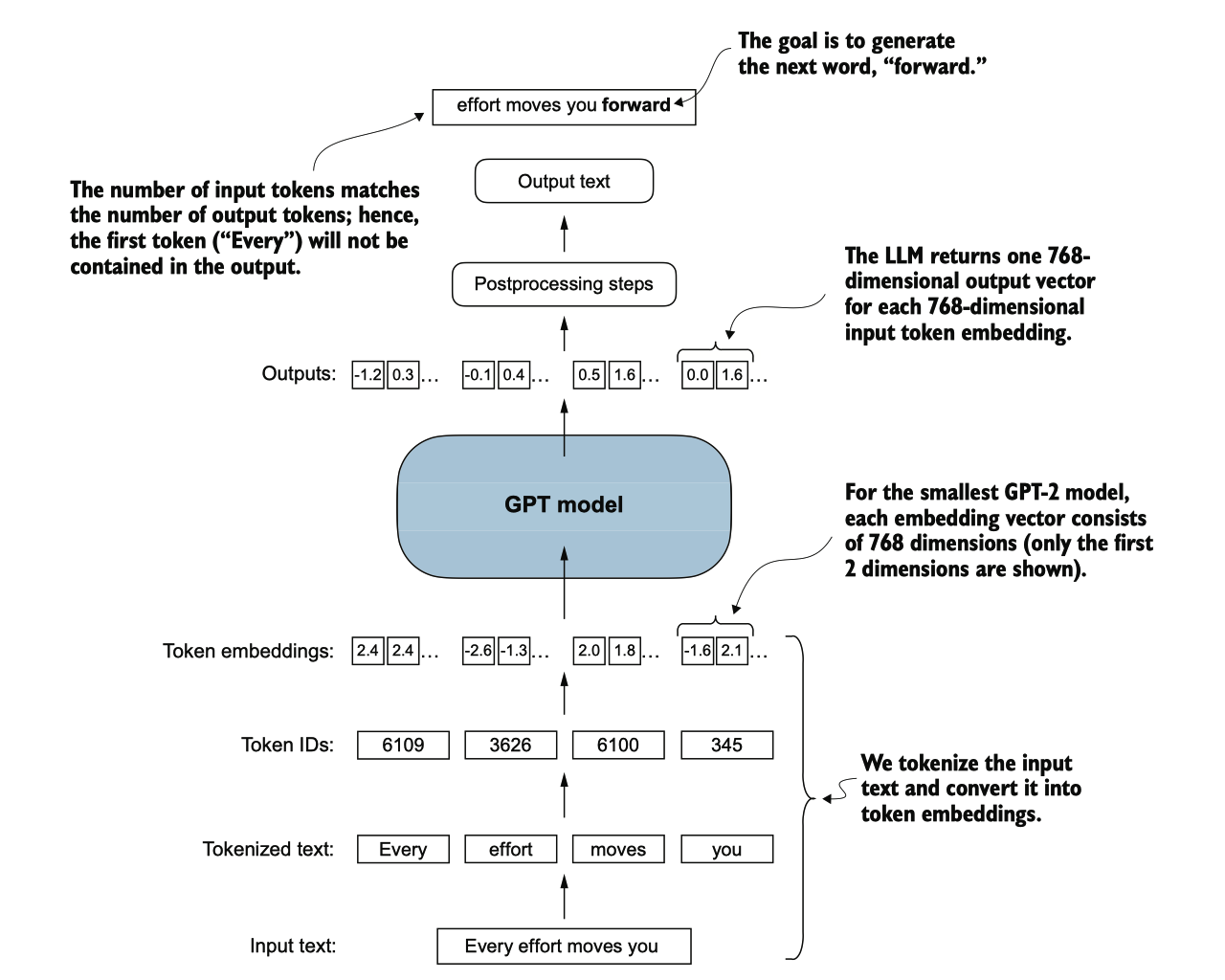
展示了输入数据如何被标记化、嵌入并送入 GPT 模型。请注意,在我们之前编码的 DummyGPTC lass 中,标记嵌入是在 GPT 模型内部处理的。在 LLMs 中,嵌入的输入标记维度通常与输出维度匹配。这里的输出 嵌入表示上下文向量
Run 124-million model
接下来,我们初始化一个新的1亿2千四百万参数的DummyGPTModel实例,并将其输入标记化的batch:
torch.manual_seed(123)
model = DummyGPTModel(GPT_CONFIG_124M)
logits = model(batch)
print("Output shape:", logits.shape)
print(logits)
## output
Output shape: torch.Size([2, 4, 50257])
tensor([[[-1.2034, 0.3201, -0.7130, ..., -1.5548, -0.2390, -0.4667],
[-0.1192, 0.4539, -0.4432, ..., 0.2392, 1.3469, 1.2430],
[ 0.5307, 1.6720, -0.4695, ..., 1.1966, 0.0111, 0.5835],
[ 0.0139, 1.6754, -0.3388, ..., 1.1586, -0.0435, -1.0400]],
[[-1.0908, 0.1798, -0.9484, ..., -1.6047, 0.2439, -0.4530],
[-0.7860, 0.5581, -0.0610, ..., 0.4835, -0.0077, 1.6621],
[ 0.3567, 1.2698, -0.6398, ..., -0.0162, -0.1296, 0.3717],
[-0.2407, -0.7349, -0.5102, ..., 2.0057, -0.3694, 0.1814]]],
grad_fn=<UnsafeViewBackward0>)
输出张量有两行,对应于两个文本样本。每个文本样本由四个标记组成;每个标记是 一个50,257维的向量,这与分词器词汇表的大小相匹配。
嵌入具有 50,257 个维度,因为这些维度中的每一个都代表词汇表中的一个独特标 记。当我们实施后处理代码时,我们将把这 50,257 维的向量转换回标记 ID,然后可 以将其解码为单词。
现在我们已经从整体上审视了GPT架构及其输入和输出,我们将开始编写各个占位 符,首先是实际的层归一化类,它将替换之前代码中的DummyLayerNorm。