Self-Attention 1. attention weight
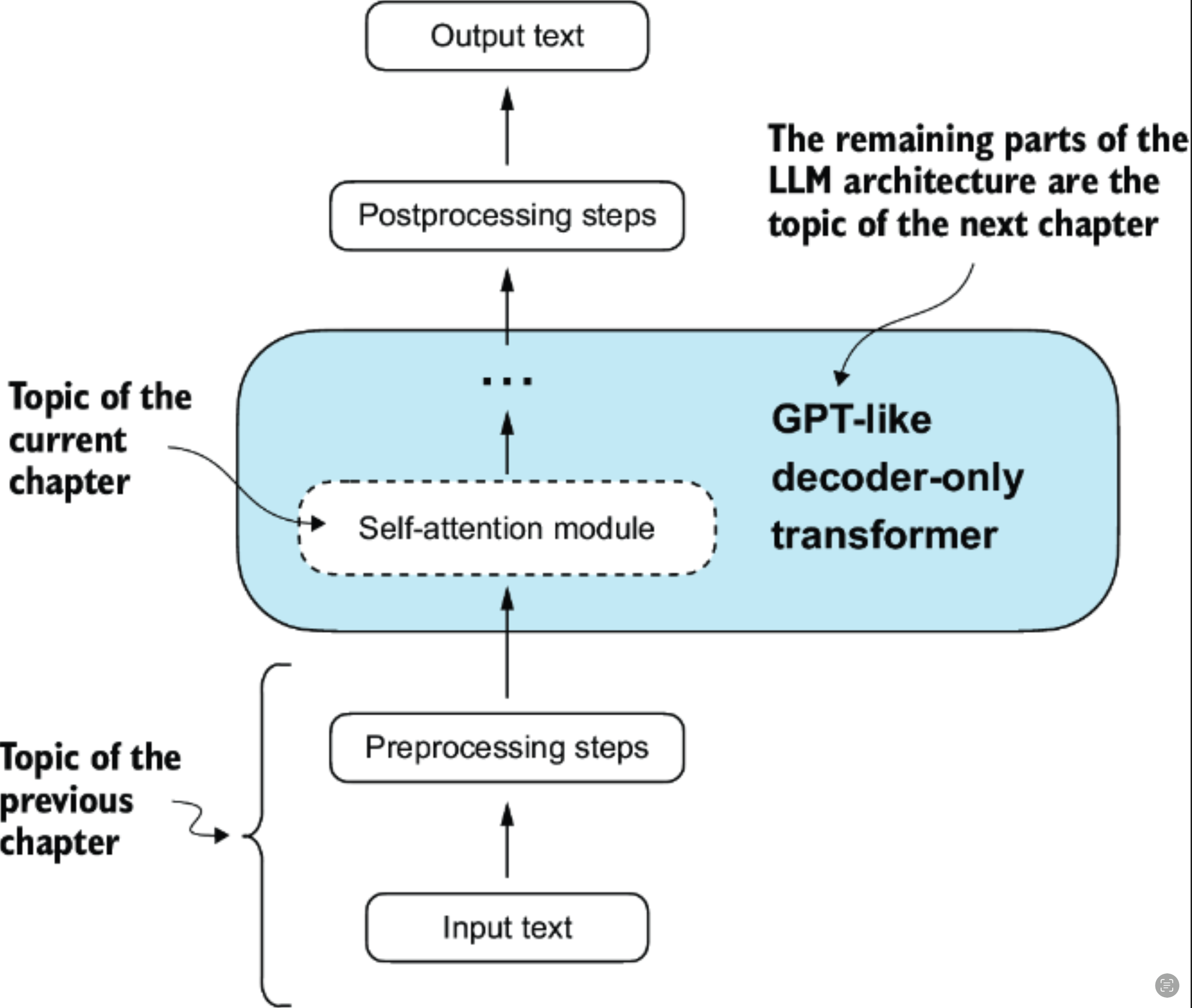
CleanShot 2024-10-21 at 7 .39.13@2x.png
自注意力是一种在变换器中使用的机制,用于通过允许序列中的每个位置与同一序列中的所有其他位置进行交互并权衡其重要性,从而计算更有效的输入表示。
"Self" in Self-Attention
在自注意力中,“自我”指的是机制通过关联单个输入序列中的不同位置来计算注意力权重的能力。它评估并学习输入自身各部分之间的关系和依赖性,如句子中的单词或图像中的像素。
这与传统的注意力机制形成对比,在传统机制中,重点是两个不同序列元素之间的关系,比如在序列到序列模型中,注意力可能集中在输入序列和输出序列之间。
简单拆解 context vector
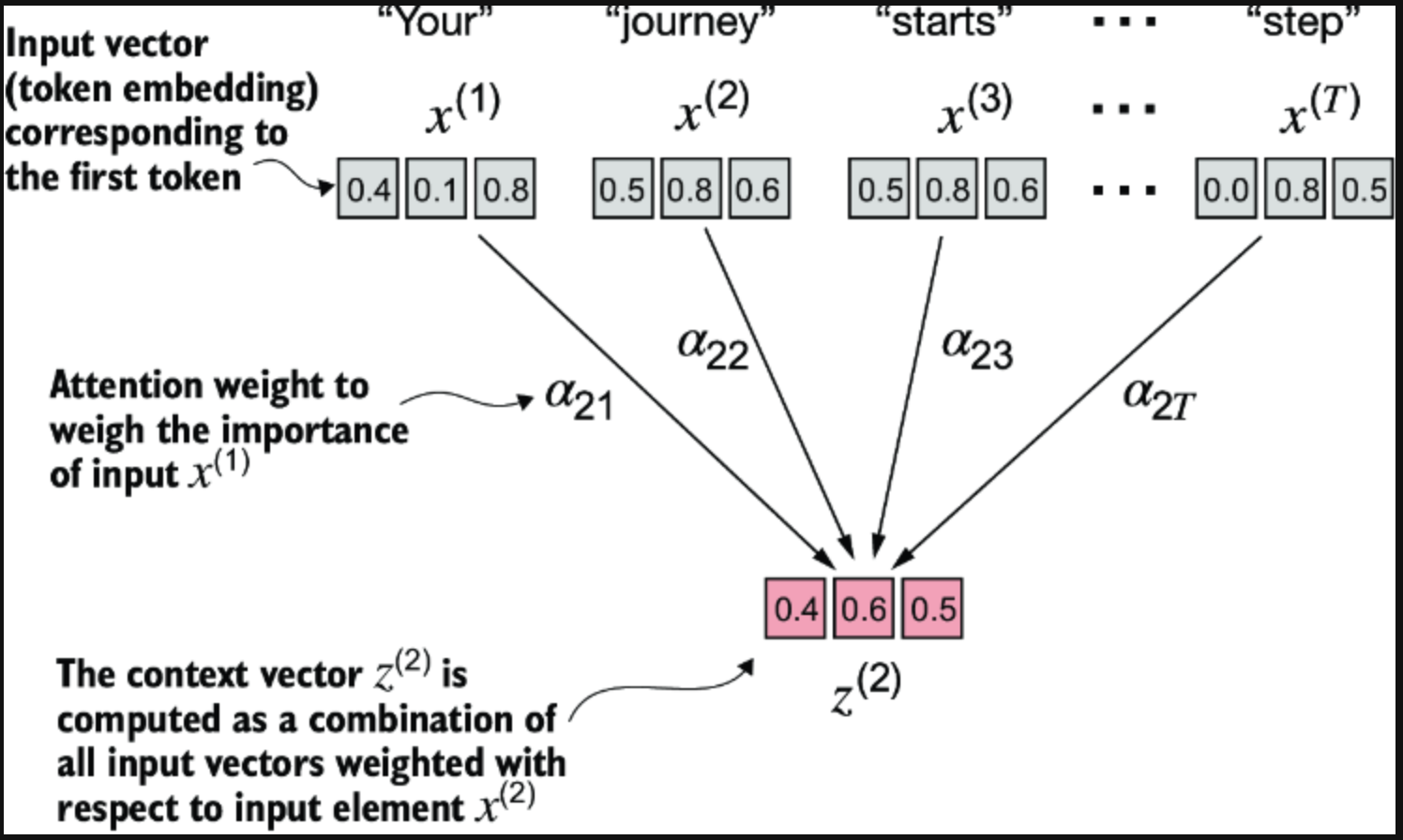
CleanShot 2024-10-21 at 8 .42.42@2x.png
考虑下 "Your journey starts with one step"这句话, 每个单词 都被three-dimensional embedding处理, 然后乘以每个其他输入值的系数a, 计算出我们的context vector 每个context vector 又都能够被interpreted为更有意义的embedding vector.
context vector在self-attention中发挥着关键作用。它们的目的是通过结合序列中所有其他元素的信息,创建输入序列(如句子)中每个元素的丰富表示。这在LLM中至关重要,因为它们需要理解句子中单词之间的关系和相关性。
计算attention score
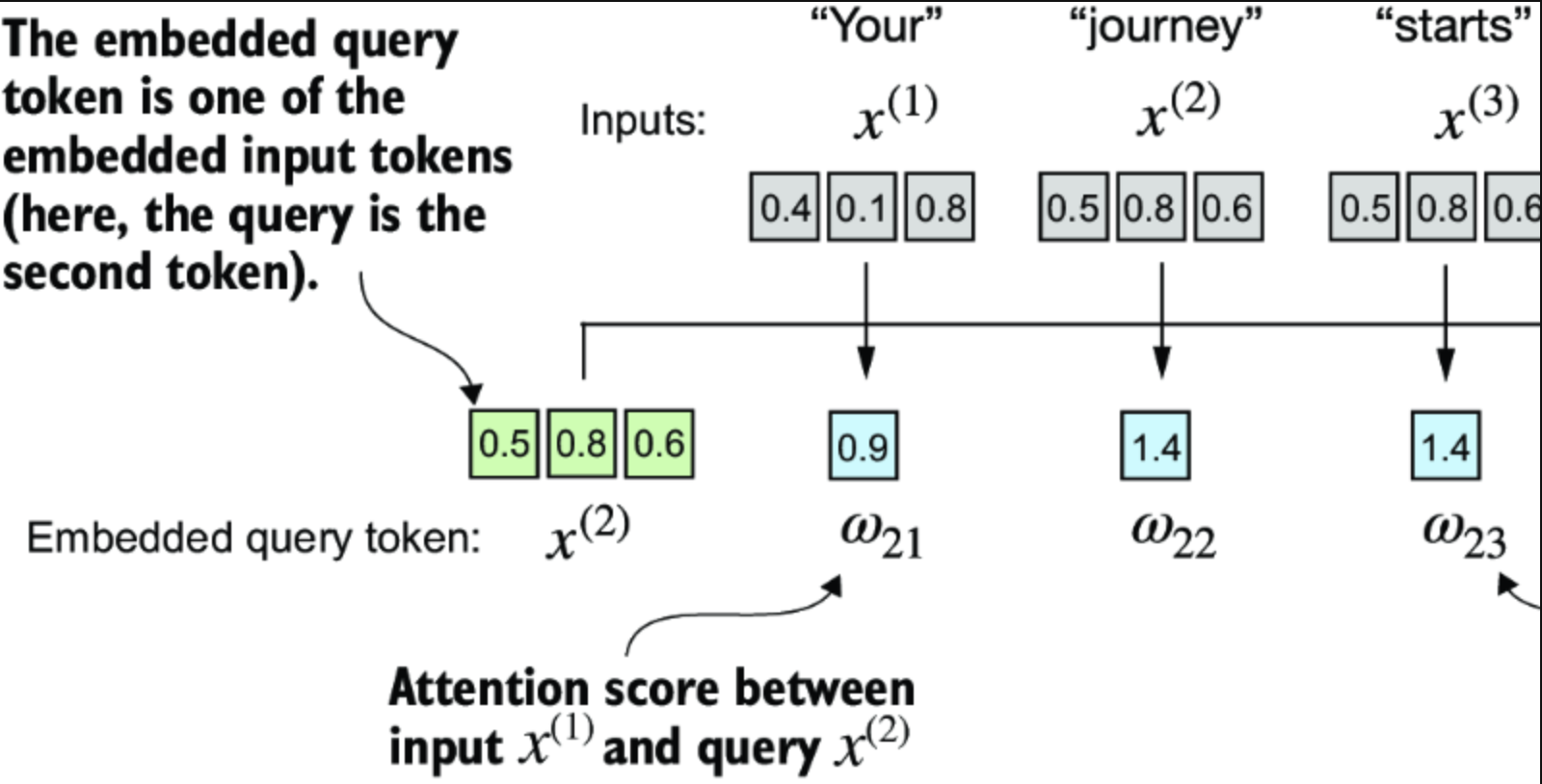
CleanShot 2024-10-22 at 7 .39.28@2x.png
上图展示的就是, 计算query 和 其他所有element之间的attention score . 作为点积(dot product)的计算.
较高的点积表明向量之间的对齐或相似程度更高。在自注意力机制的背景下,点积决定了序列中每个元素对任何其他元素的关注或“注意”程度:点积越高,两个元素之间的相似性和注意分数就越高。
normalize attention score
归一化(normalize)的主要目标是获得总和为1的注意力权重。这种归一化是一种约定,对于解释和维持大型语言模型(LLM)的训练稳定性是有用的
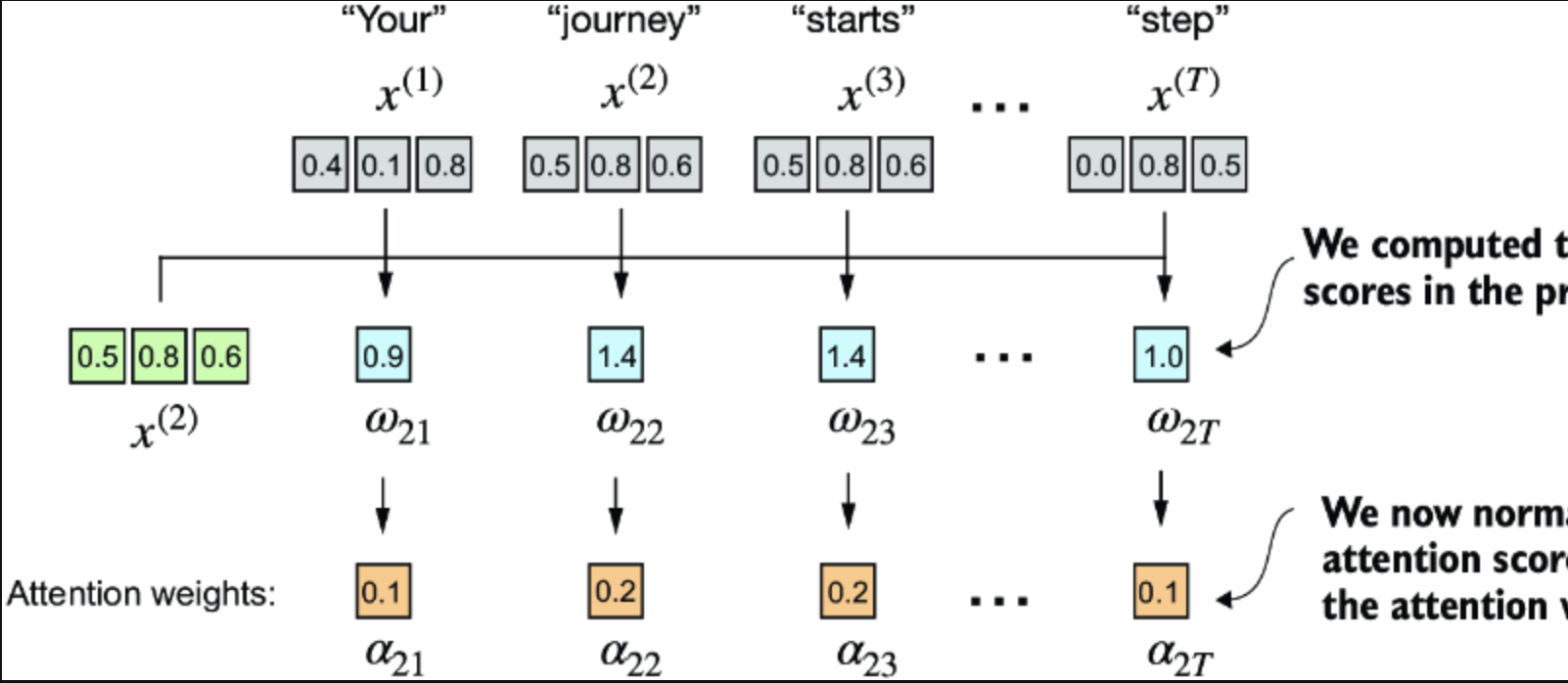
CleanShot 2024-10-22 at 7 .54.19@2x.png
归一化后结果如下
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656]) Sum: tensor(1.0000)
compute context vector
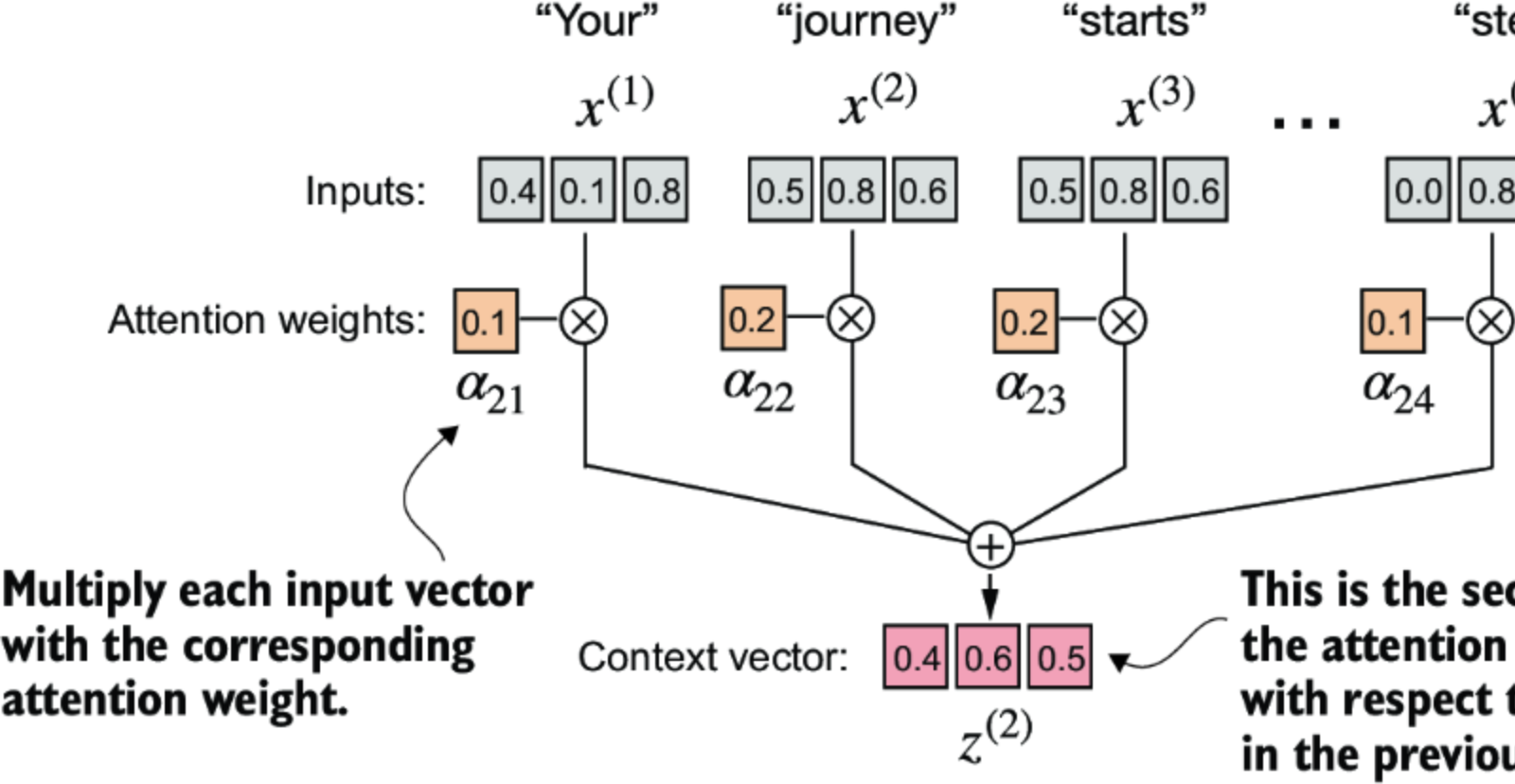
CleanShot 2024-10-22 at 8 .13.30@2x.png
在计算并归一化attention score以获得查询 的注意力权重后,接下来是计算上下文向量 。该上下文向量是所有输入向量 到 按照注意力权重加权的组合。
为所有input tokens计算attention weights
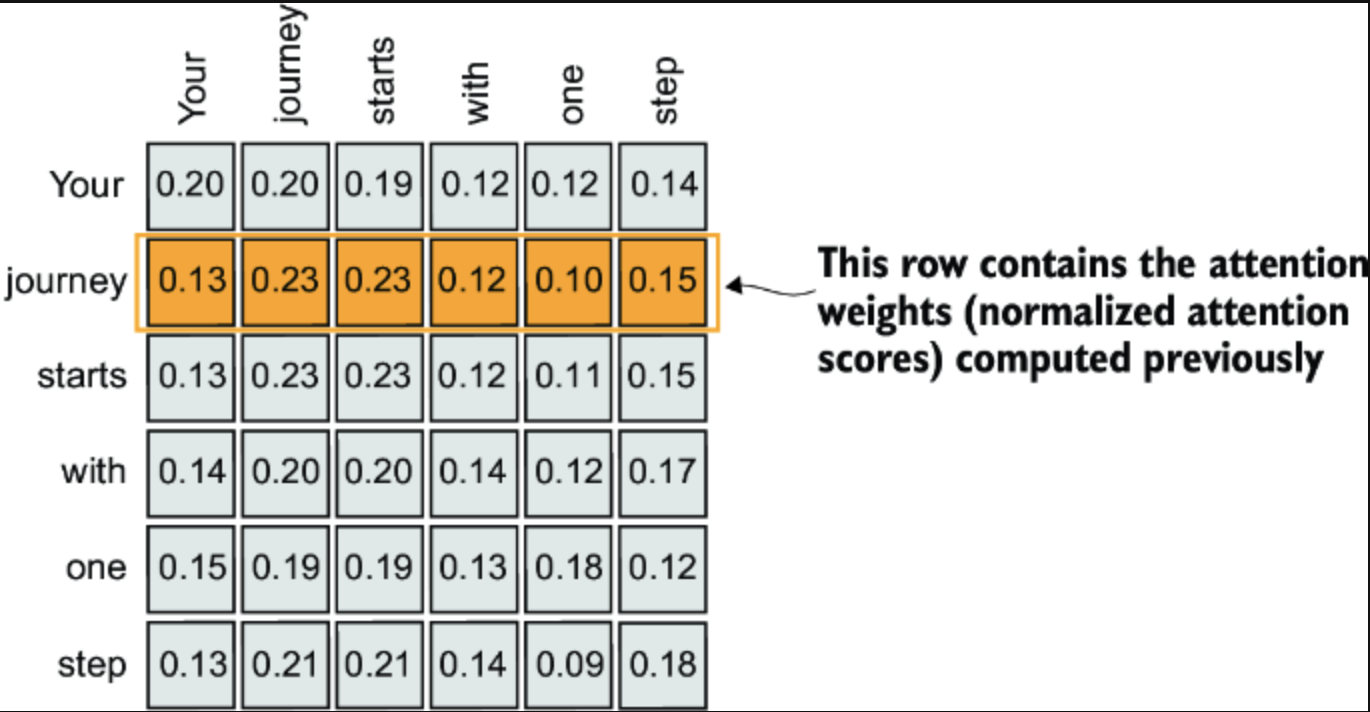
CleanShot 2024-10-23 at 7 .48.40@2x.png
第二行就是我们为 计算的 attention weight
再来回顾一下之前计算的方式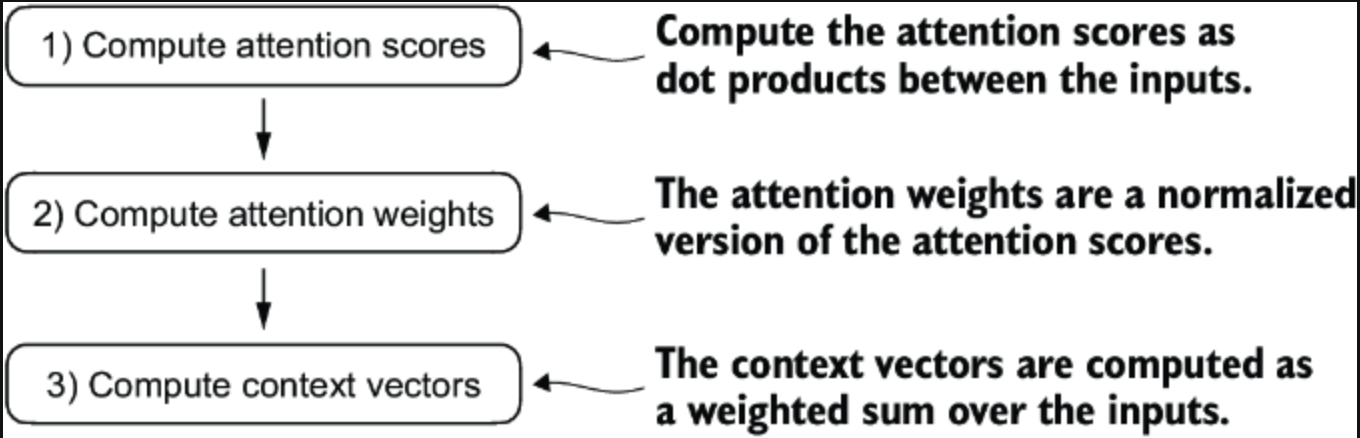
CleanShot 2024-10-23 at 7 .50.30@2x.png