Self-Attention 2. trainable weights
trainable weights 与之前的相比, 最大的不同是在于 weight matrices 再大模型训练期间是更新的.
First. compute attention weight
CleanShot 2024-10-23 at 8 .04.16@2x.png
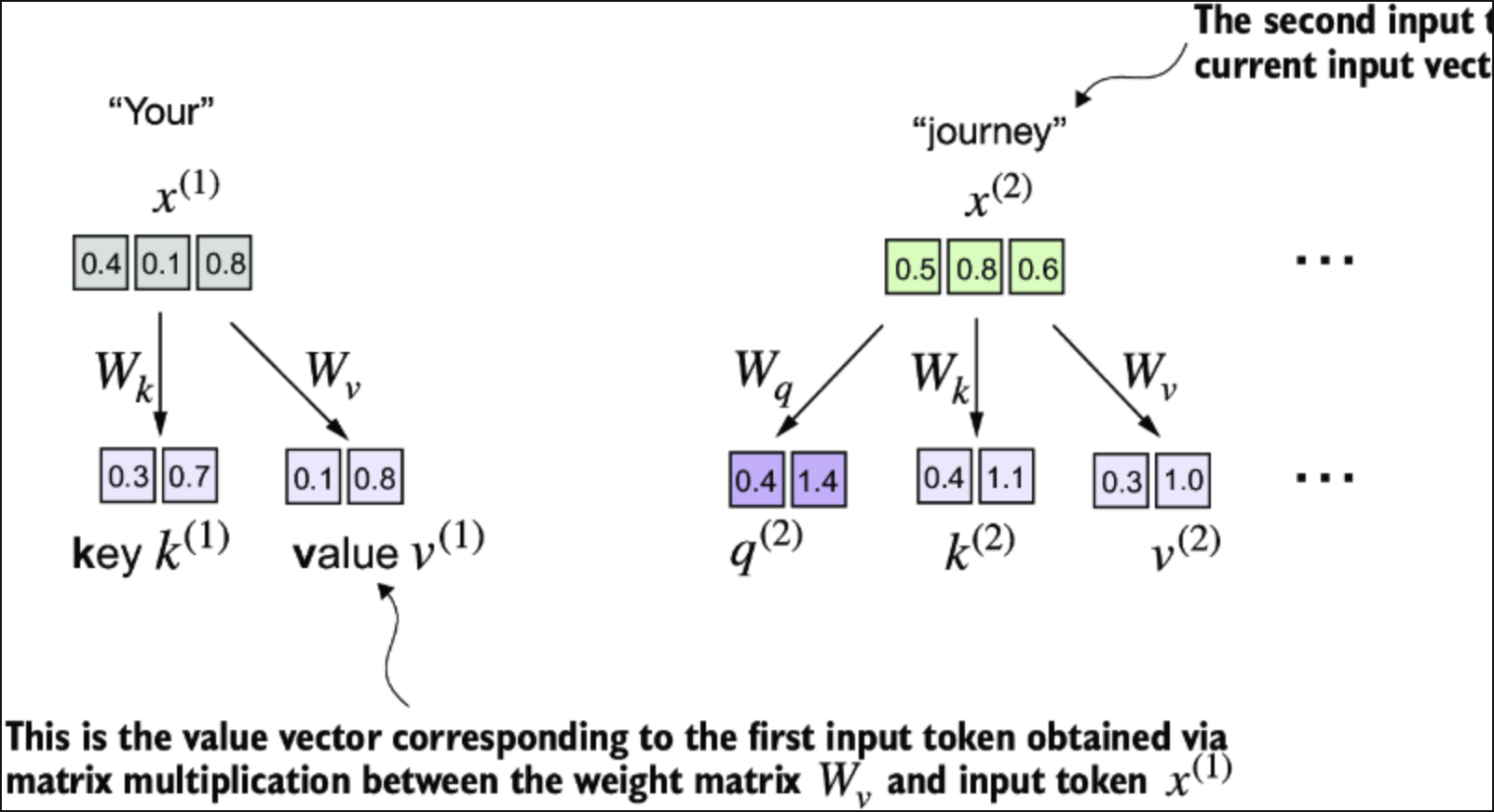
在带有可训练权重矩阵(Weight Matrix)的自注意力机制的第一步中,我们为输入元素 x 计算query (q)、key (k) 和 value (v) 向量。与前面的部分类似,我们将第二个输入 指定为查询输入。查询向量 通过输入 与权重矩阵 之间的矩阵乘法获得。同样,我们通过涉及权重矩阵 和 的矩阵乘法获得键向量和值向量。
尽管我们暂时的目标仅仅是计算一个上下文向量 ,但我们仍然需要所有输入元素的key和value向量,因为它们参与了计算相对于 的注意力权重。
Weight parameters VS Attention weights
在权重矩阵 W 中,“权重”一词是“权重参数”的缩写,指的是在训练过程中优化的神经网络的值。这与注意力权重并不相同。正如我们之前所看到的,注意力权重决定了上下文向量在多大程度上依赖于输入的不同部分(即网络在多大程度上关注输入的不同部分)。
总之,权重参数是定义网络连接的基本学习系数,而注意力权重则是动态的、特定于上下文的值。
Second. Compute attention score
CleanShot 2024-10-23 at 8 .15.34@2x.png
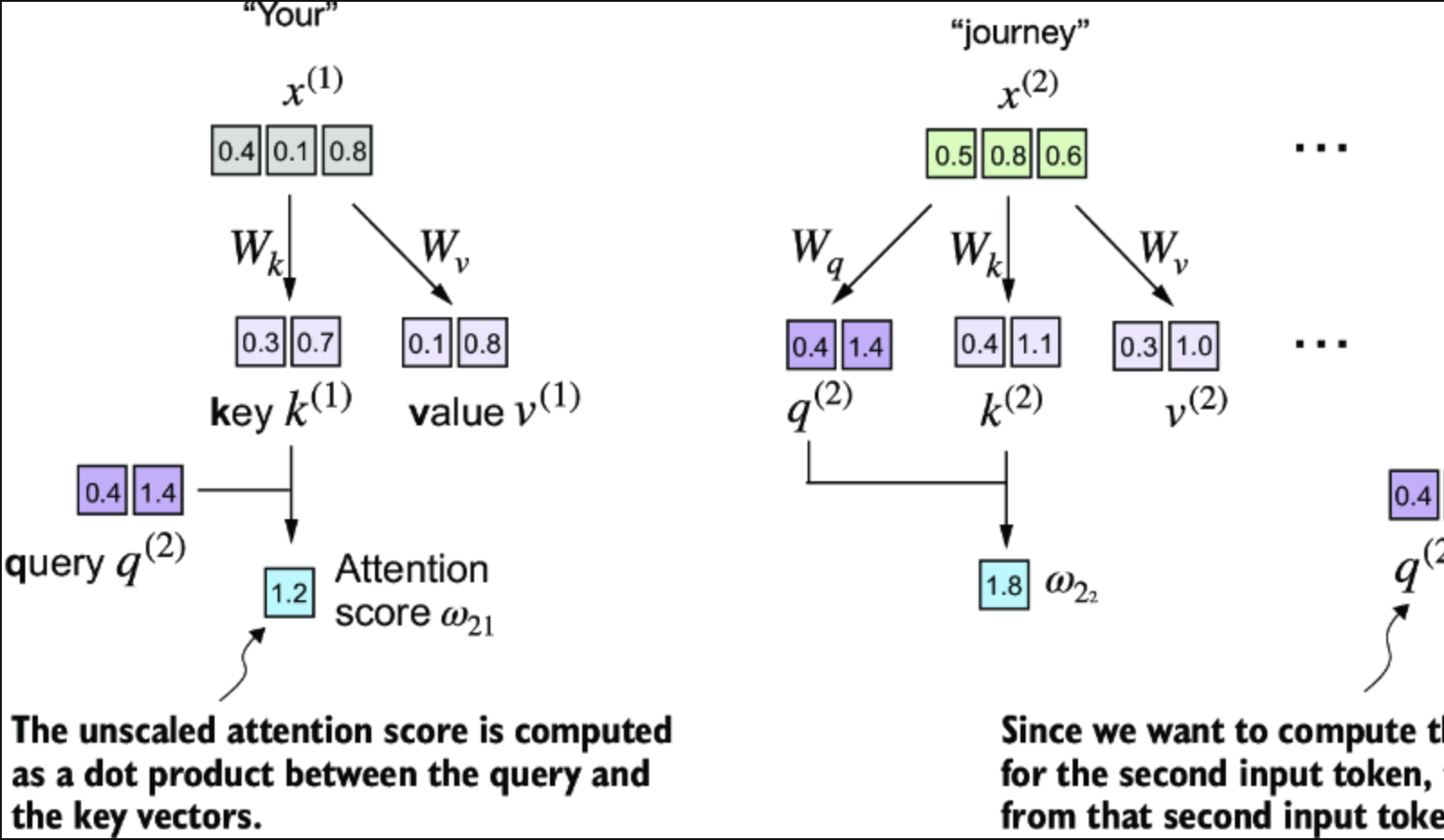
这里的新特征在于,我们并不是直接计算输入元素之间的点积,而是使用通过相应权重矩阵变换输入后得到的查询和键。
keys_2 = keys[1] #1 第二个元素
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22) # w22
计算所有的attention score 对于第二元素
attn_scores_2 = query_2 @ keys.T #1
print(attn_scores_2)
attention score结果如下
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])
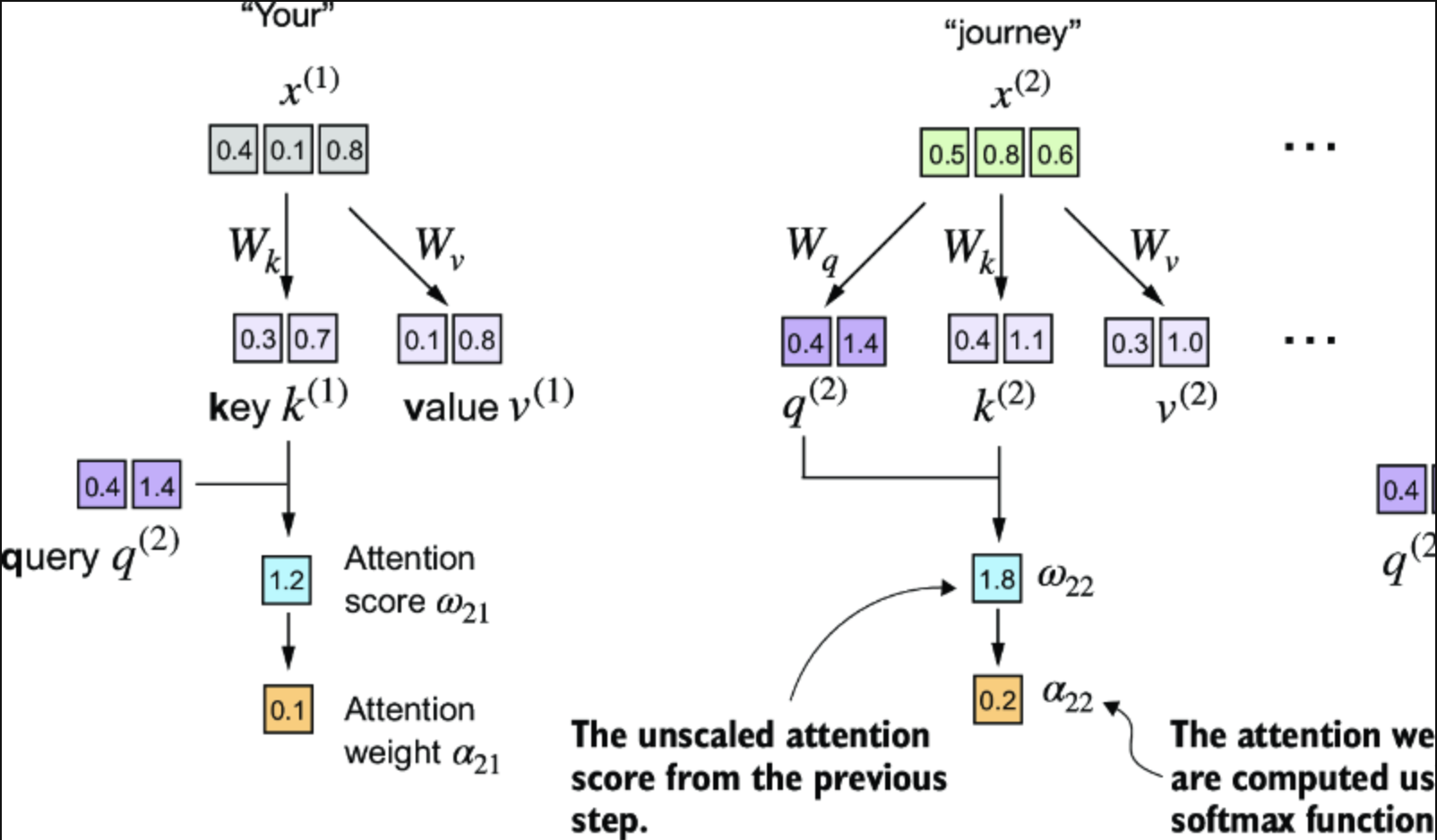
Third. normalize attention score
CleanShot 2024-10-23 at 8 .22.21@2x.png
最终attention weight如下
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
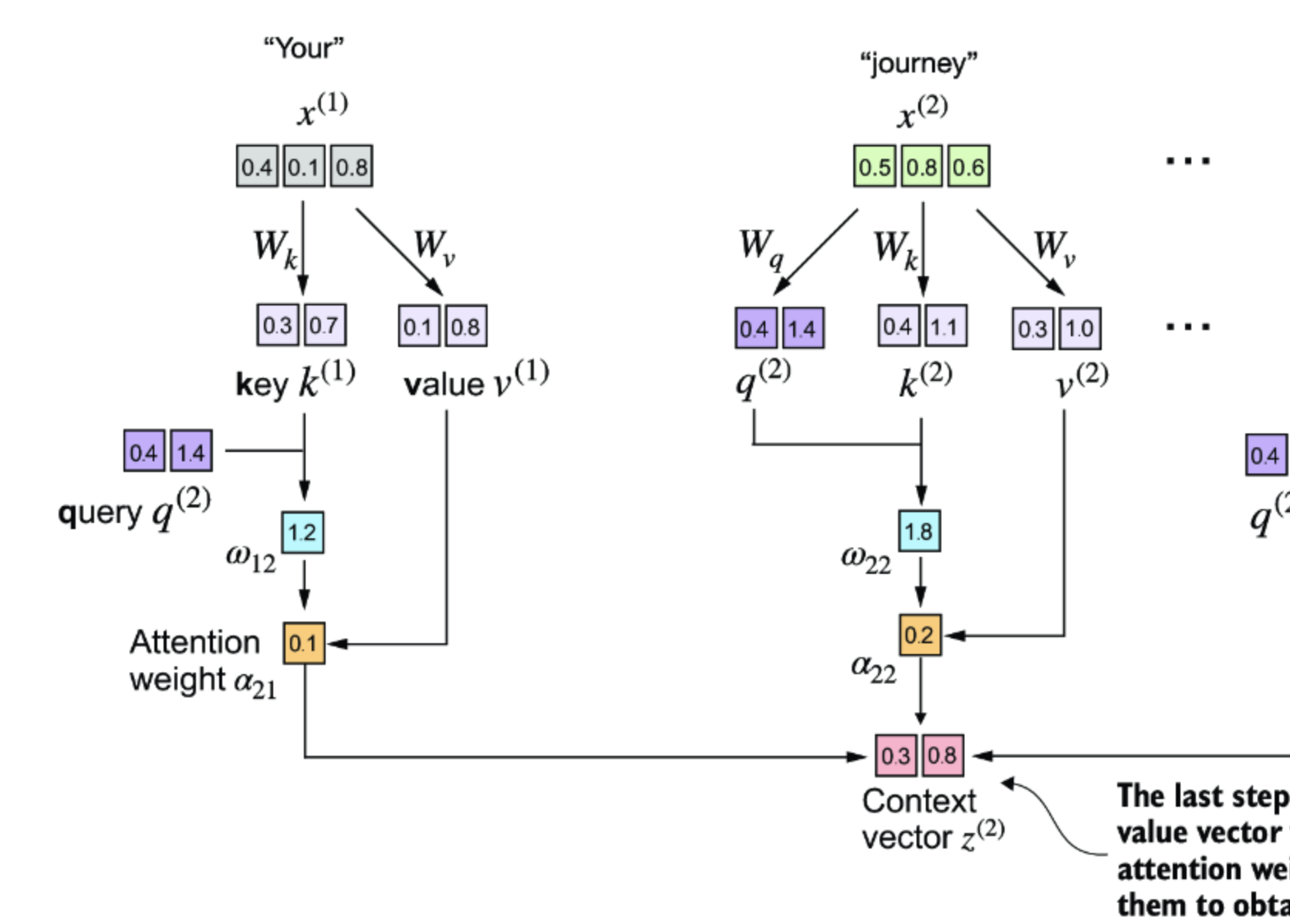
Forth. compute context vector
CleanShot 2024-10-28 at 11 .19.26@2x.png
现在将上下文向量(context vector)计算为值向量(value vector)的加权和。在这里,注意力权重作为加权因子,权衡每个值向量的相对重要性。
context_vec_2 = attn_weights_2 @ values
print(context_vec_2)
目前为止, 我们只计算了 接下来是需要生成 到 所有的Context Vector
Query & Key & Value
在注意力机制的上下文中,“键”、“查询”和“值”这几个术语是借鉴自信息检索和数据库领域,在那里类似的概念用于存储、搜索和检索信息。
查询类似于数据库中的搜索查询。它代表模型所关注或试图理解的当前项目(例如,句子中的一个词或标记)。查询用于探查输入序列的其他部分,以确定应给予它们多少关注。
键类似于用于索引和搜索的数据库键。在注意力机制中,输入序列中的每个项目(例如,句子中的每个词)都有一个关联的键。这些键用于与查询匹配。
在这个上下文中,值类似于数据库中键值对中的值。它代表输入项目的实际内容或表示。一旦模型确定哪些键(因此哪些输入部分)与查询(当前关注的项目)最相关,它就会检索相应的值。