Self-Attention 3. Causal attention
在很多大模型任务中, 通常希望自注意力机制在预测序列中的下一个标记时,仅考虑当前位点之前出现的标记。
Causal attention 又叫做 Masked attention.
限制大模型在计算attention score时, 仅考虑当前序列中的前一个和当前输入. 与上节对比的话, 标准的attention mechanism,允许一次性反问所有的序列
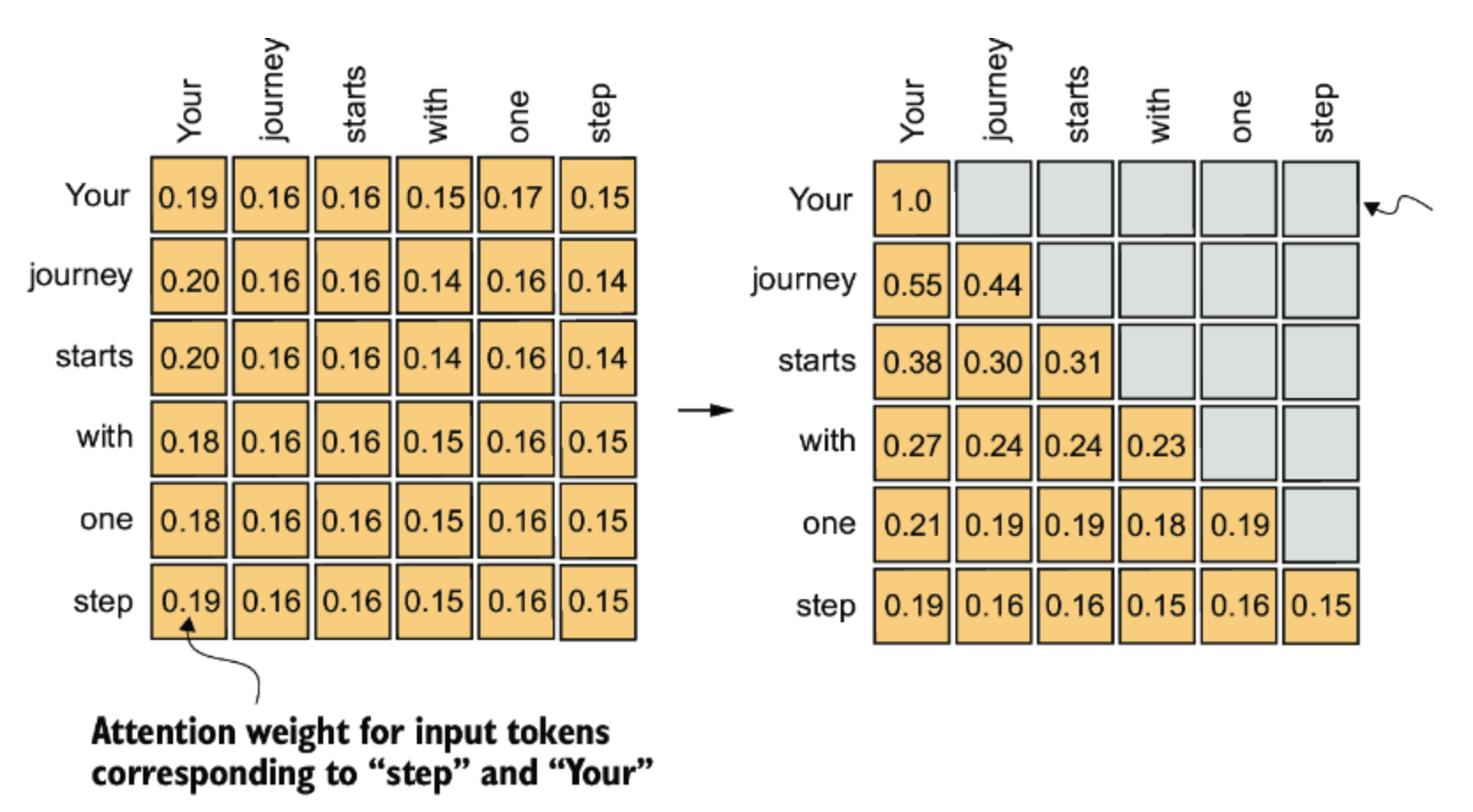
CleanShot 2024-10-30 at 12 .13.12@2x.png
以上图例中, 就是屏蔽序列中当前输入后面的文本, 然后normalize后的结果.
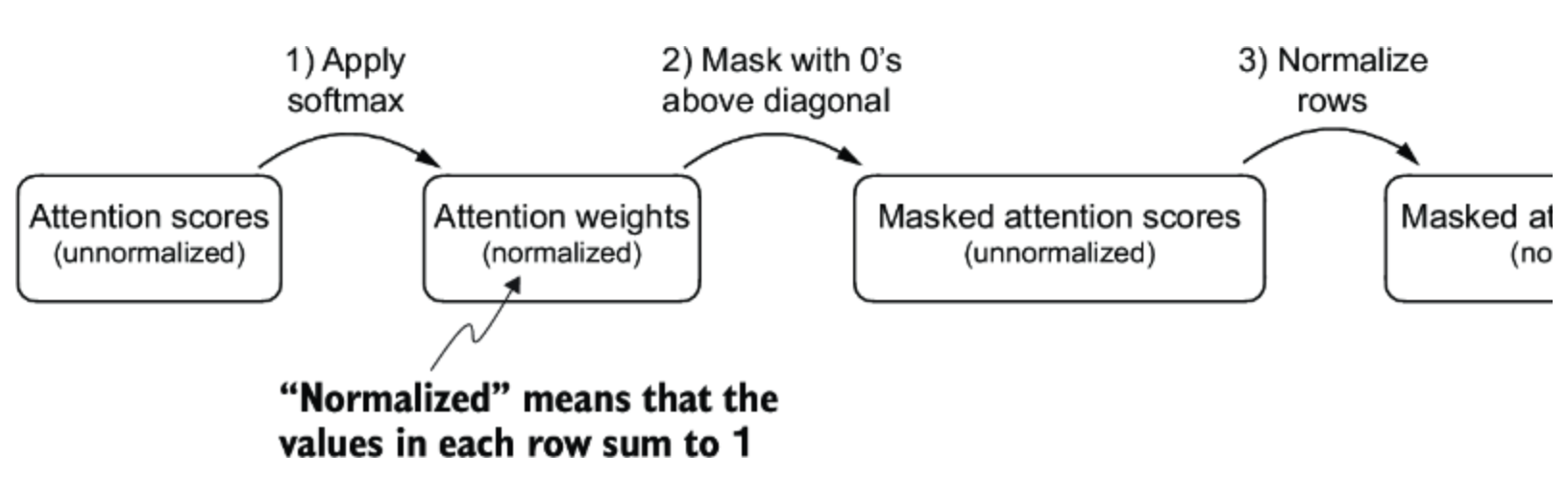
First. apply a causal attention mask
CleanShot 2024-10-30 at 12 .15.27@2x.png
queries = sa_v2.W_query(inputs) #1
keys = sa_v2.W_key(inputs)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
print(attn_weights)
## result
tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],
[0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],
[0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],
[0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],
[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]], grad_fn=<SoftmaxBackward0>)
以上是之前计算标准attention mechanism中attention score的流程, 这里可以使用PyTorch中的tril方法来创建一个mask
context_length = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(context_length, context_length)) print(mask_simple)
## result
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])
masked_simple = attn_weights*mask_simple
print(masked_simple)
## result
tensor([[0.1921, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2041, 0.1659, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2036, 0.1659, 0.1662, 0.0000, 0.0000, 0.0000],
[0.1869, 0.1667, 0.1668, 0.1571, 0.0000, 0.0000],
[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]], grad_fn=<MulBackward0>)
然后在renormalize一下
row_sums = masked_simple.sum(dim=-1, keepdim=True)
masked_simple_norm = masked_simple / row_sums print(masked_simple_norm)
## result
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]], grad_fn=<DivBackward0>)
improve mask step 优化以上流程
利用softmax函数的一个数学属性, 更高效地在更少的步骤中实现掩蔽注意力权重的计算。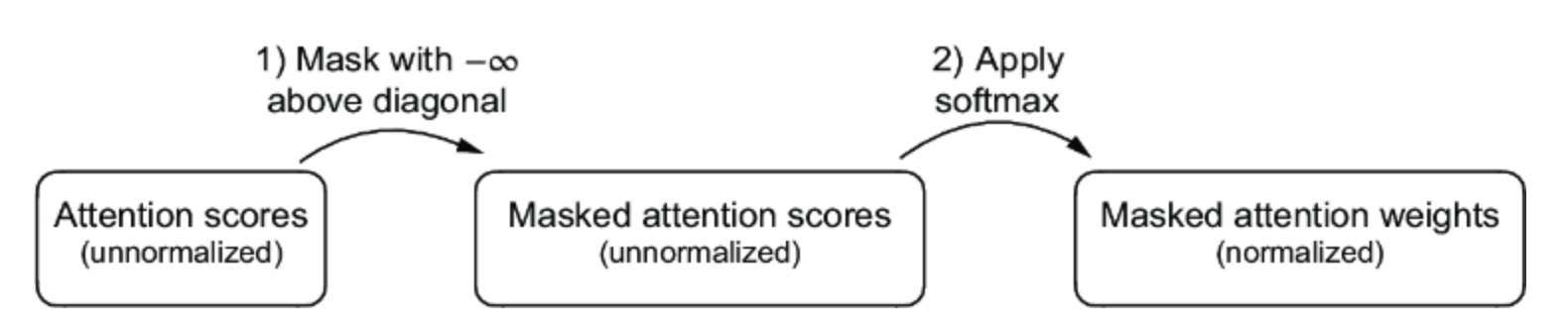
CleanShot 2024-10-30 at 12 .24.54@2x.png
softmax函数将其输入转换为概率分布。当一行中存在负无穷值(-∞)时,softmax函数将其视为零概率。(从数学上讲,这是因为e –∞趋近于0。)
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf) print(masked)
## result
tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],
[0.4656, 0.1723, -inf, -inf, -inf, -inf],
[0.4594, 0.1703, 0.1731, -inf, -inf, -inf],
[0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],
[0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],
[0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]], grad_fn=<MaskedFillBackward0>)
attn_weights = torch.softmax(masked / keys.shape[-1]**0.5, dim=1) print(attn_weights)
## result
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]], grad_fn=<SoftmaxBackward0>)
self-attention mechanism的一个小调整,这对于在训练大型语言模型时减少过拟合非常有用。
Second. masking additional attention weights with dropout
深度学习中的 dropout 是一种技术,在训练过程中随机选择的隐藏层单元被忽略,这实际上是“丢弃”它们。 主要目的是为了防止overfitting
在构建llm model的时候, 会有两次使用dropout.
- 在计算完attention weights之后
- 在应用attention weights到 vector之后
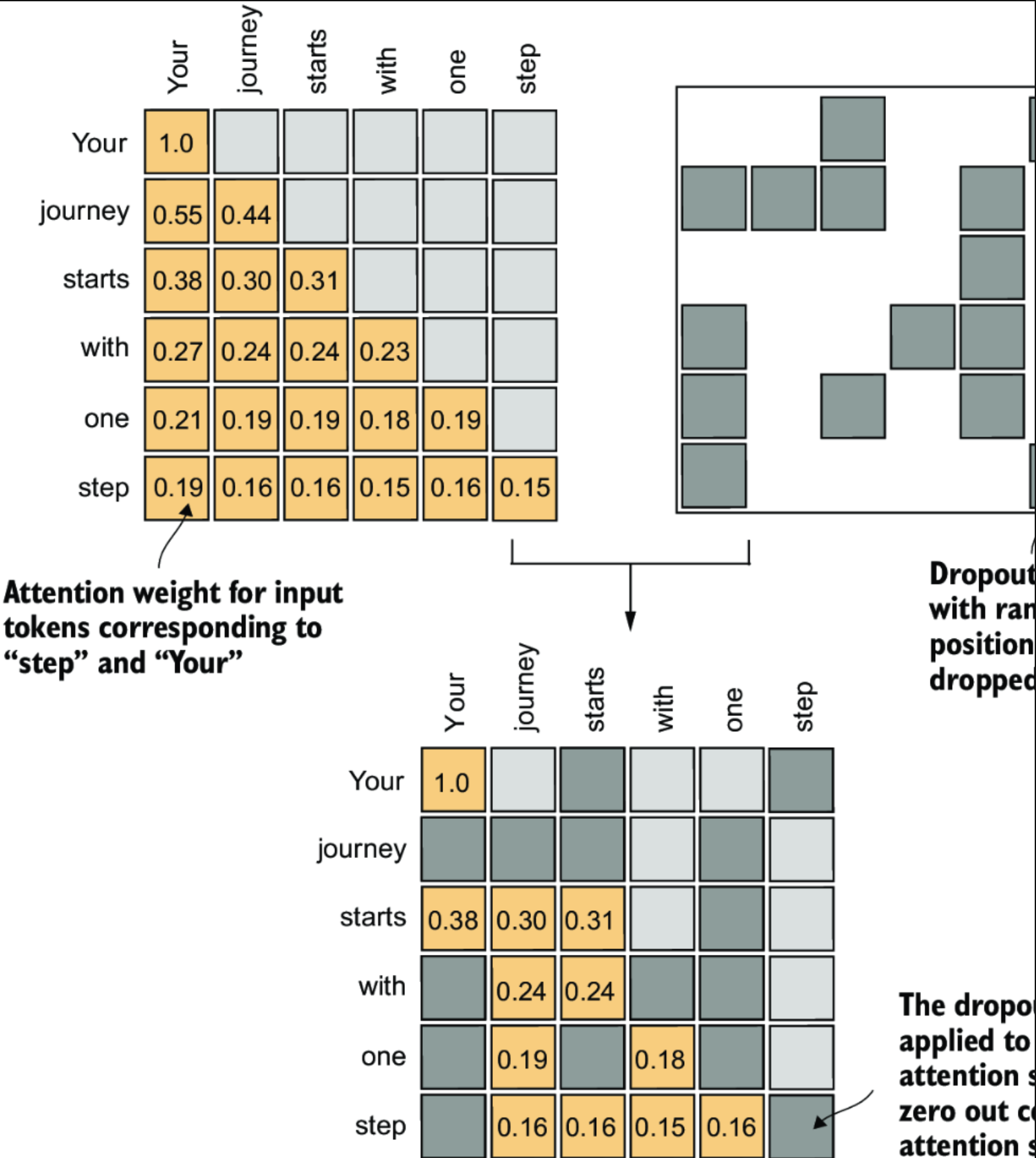
使用Dropout mask 应用到Attention mask
torch.manual_seed(123)
dropout = torch.nn.Dropout(0.5) #1
example = torch.ones(6, 6) #2
print(dropout(example))
## result
tensor([[2., 2., 0., 2., 2., 0.],
[0., 0., 0., 2., 0., 2.],
[2., 2., 2., 2., 0., 2.],
[0., 2., 2., 0., 0., 2.],
[0., 2., 0., 2., 0., 2.],
[0., 2., 2., 2., 2., 0.]])
torch.manual_seed(123) # apply
print(dropout(attn_weights))
## result
tensor([[2.0000, 0.0000, 0 .0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],
[0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],
[0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],
[0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]], grad_fn=<MulBackward0>
Code
import torch
import torch.nn as nn
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
# Register a causal mask buffer
self.register_buffer(
'mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# Compute keys, queries, and values
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
# Compute attention scores
attn_scores = queries @ keys.transpose(1, 2)
# Apply causal mask
attn_scores.masked_fill_(
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf
)
# Compute attention weights
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
# Apply dropout to attention weights
attn_weights = self.dropout(attn_weights)
# Compute the context vector
context_vec = attn_weights @ values
return context_vec
Where is us?
Here’s what we’ve done so far.
我们首先从一个简化的注意力机制开始,添加了可训练的权重,然后添加了因果注意力掩码。接下来,我们将扩展因果注意力机制并编码多头注意力,这将在我们的LLM中使用。